| MapReduce入门(一) | 您所在的位置:网站首页 › mapreduce mapxml › MapReduce入门(一) |
MapReduce入门(一)
|
MapReduce入门(一)—— MapReduce概述
文章目录
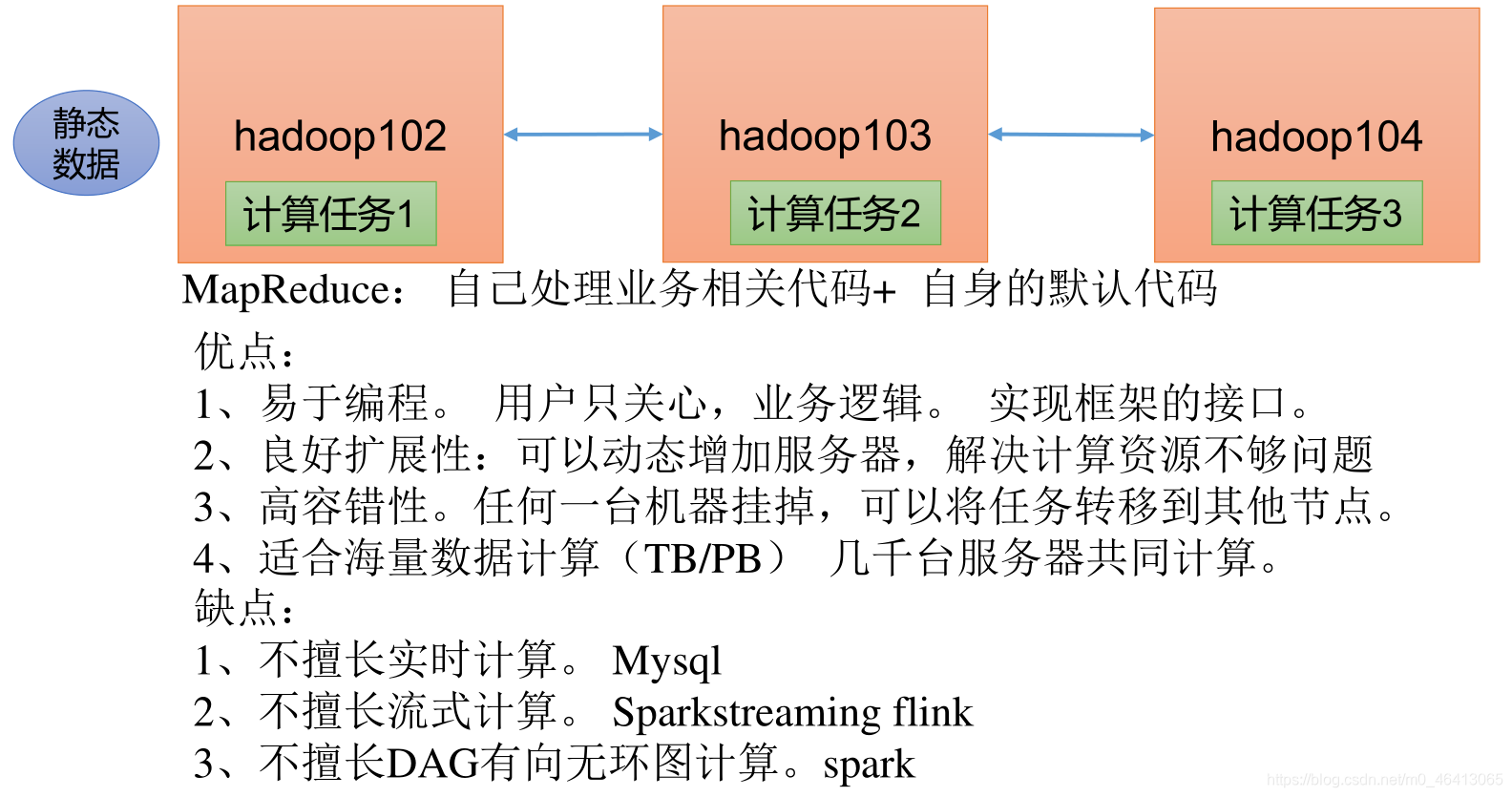
MapReduce入门(一)—— MapReduce概述1.1 MapReduce 定义1.2 MapReduce 优缺点1.2.1 优点1 )MapReduce 易于编程2 ) 良好的扩展性3 ) 高容错性4 ) 适合 PB 级以上海量数据的离线处理
1.2.2 缺点1 ) 不擅长实时计算2 ) 不擅长流式计算3 ) 不擅长 DAG (有向无环图)计算
1.3 MapReduce 核心编程思想1.4 MapReduce 进程1.5 官方 WordCount 源码1.6 常用数据 序列化类型1.7 MapReduce 编程规范1.Mapper阶段2.Reducer阶段3.Driver阶段
1.8 WordCount 案例实操1.8.1 本地测试1 ) 需求2 ) 需求分析3 ) 环境准备4 ) 编写程序(1)编写 Mapper 类(2)编写 Reducer 类(3)编写 Driver 驱动类
5 ) 本地测试
1.8.2 WordCount案例Debug调试1.8.3 提交到集群测试(1)用 maven 打 jar 包,需要添加的打包插件依赖(2)将程序打成 jar 包(3)修改不带依赖的 jar 包名称为 wc.jar,并拷贝该 jar 包到 Hadoop 集群的/opt/module/hadoop-3.1.3 路径(4)启动 Hadoop 集群(5)执行 WordCount 程序
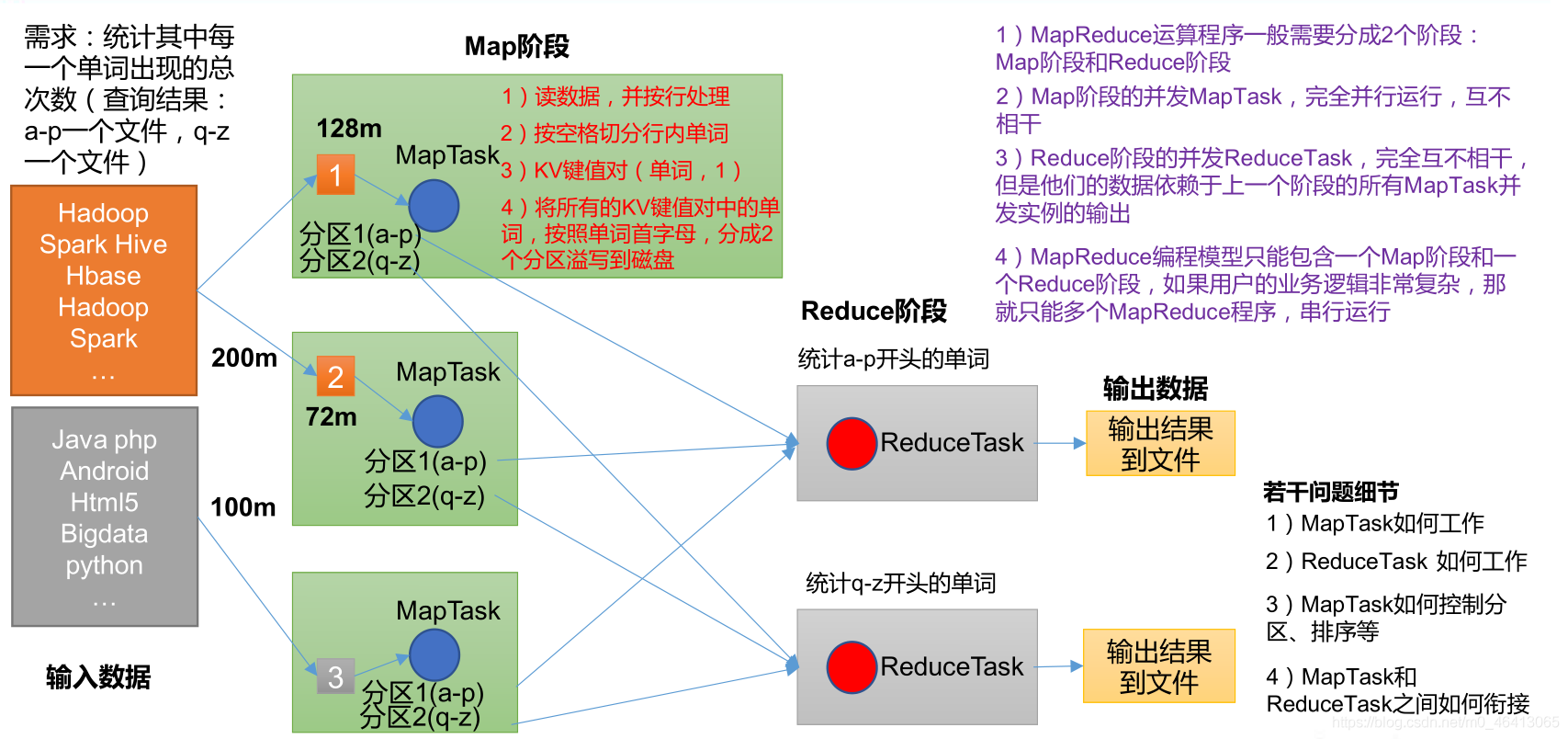
MapReduce知识点总览图 MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 Hadoop 的数据分析应用”的核心框架。 MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。 它简单的实现一些接口, 就可以完成一个分布式程序, 这个分布式程序可以分布到大量廉价的 PC 机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得 MapReduce 编程变得非常流行。 2 ) 良好的扩展性当你的计算资源不能得到满足的时候, 你可以通过简单的增加机器来扩展它的计算能力。 3 ) 高容错性MapReduce 设计的初衷就是使程序能够部署在廉价的 PC 机器上, 这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败, 而且这个过程不需要人工参与, 而完全是由Hadoop内部完成的。 4 ) 适合 PB 级以上海量数据的离线处理可以实现上千台服务器集群并发工作,提供数据处理能力。 1.2.2 缺点 1 ) 不擅长实时计算MapReduce 无法像 MySQL 一样,在毫秒或者秒级内返回结果。 2 ) 不擅长流式计算流式计算的输入数据是动态的, 而 MapReduce 的输入数据集是静态的, 不能动态变化。 这是因为 MapReduce 自身的设计特点决定了数据源必须是静态的。 3 ) 不擅长 DAG (有向无环图)计算多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce 并不是不能做, 而是使用后, 每个 MapReduce 作业的输出结果都会写入到磁盘,会造成大量的磁盘 IO,导致性能非常的低下。 1.3 MapReduce 核心编程思想
(1)分布式的运算程序往往需要分成至少 2 个阶段。 (2)第一个阶段的 MapTask 并发实例,完全并行运行,互不相干。 (3)第二个阶段的 ReduceTask 并发实例互不相干,但是他们的数据依赖于上一个阶段的所有 MapTask 并发实例的输出。 (4)MapReduce 编程模型只能包含一个 Map 阶段和一个 Reduce 阶段,如果用户的业务逻辑非常复杂,那就只能多个 MapReduce 程序,串行运行。 总结:分析 WordCount 数据流走向深入理解 MapReduce 核心思想。 1.4 MapReduce 进程一个完整的 MapReduce 程序在分布式运行时有三类实例进程: (1)MrAppMaster:负责整个程序的过程调度及状态协调。 (2)MapTask:负责 Map 阶段的整个数据处理流程。 (3)ReduceTask:负责 Reduce 阶段的整个数据处理流程。 1.5 官方 WordCount 源码采用反编译工具反编译源码,发现 WordCount 案例有 Map 类、Reduce 类和驱动类。且数据的类型是 Hadoop 自身封装的序列化类型。 先下载官方源码:
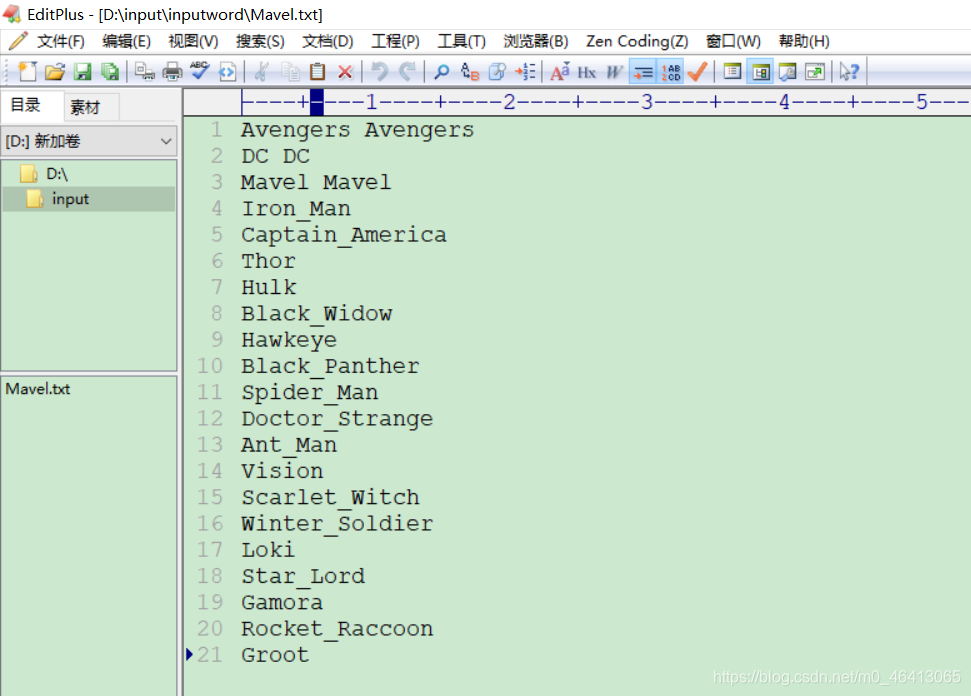
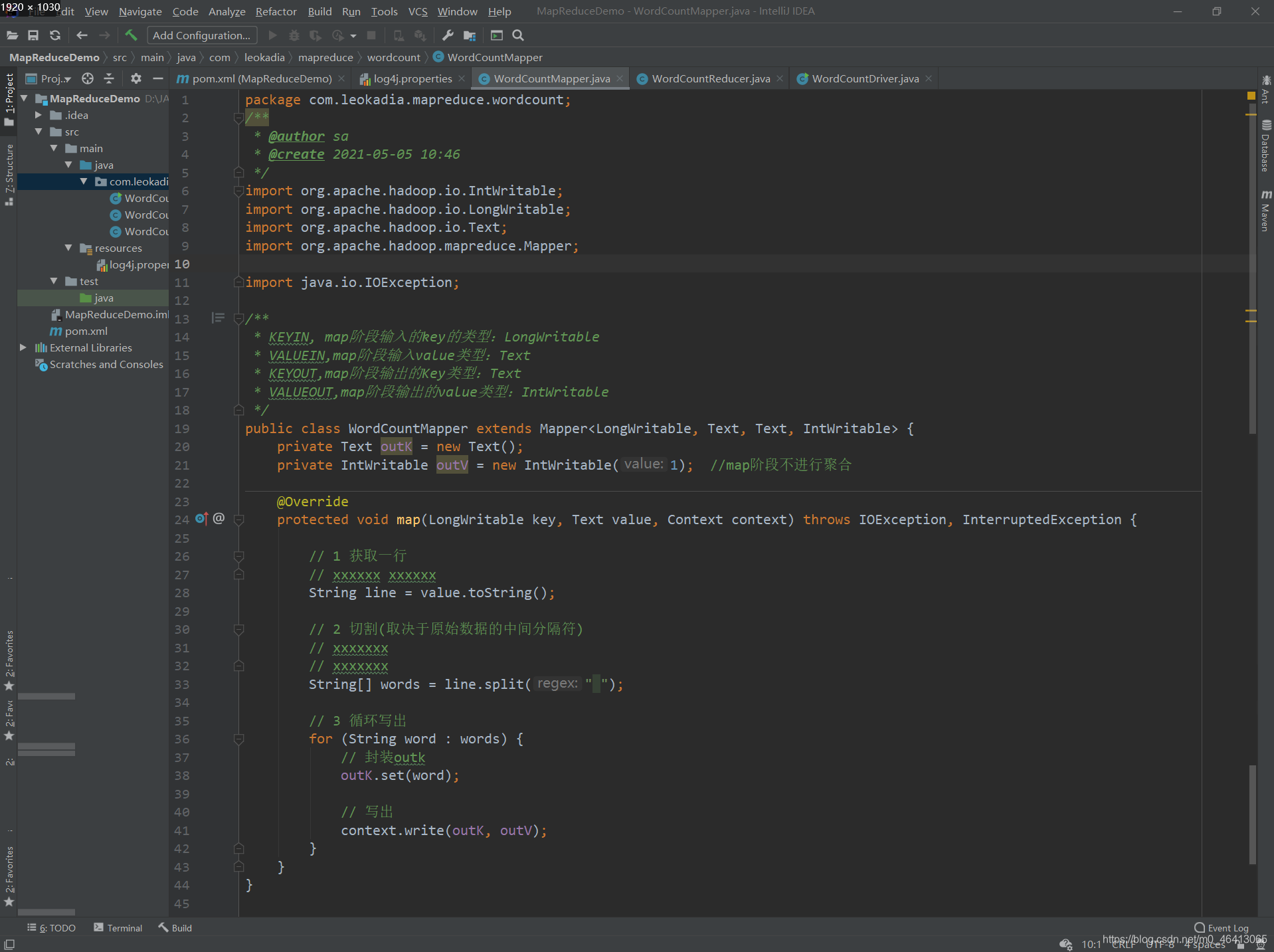
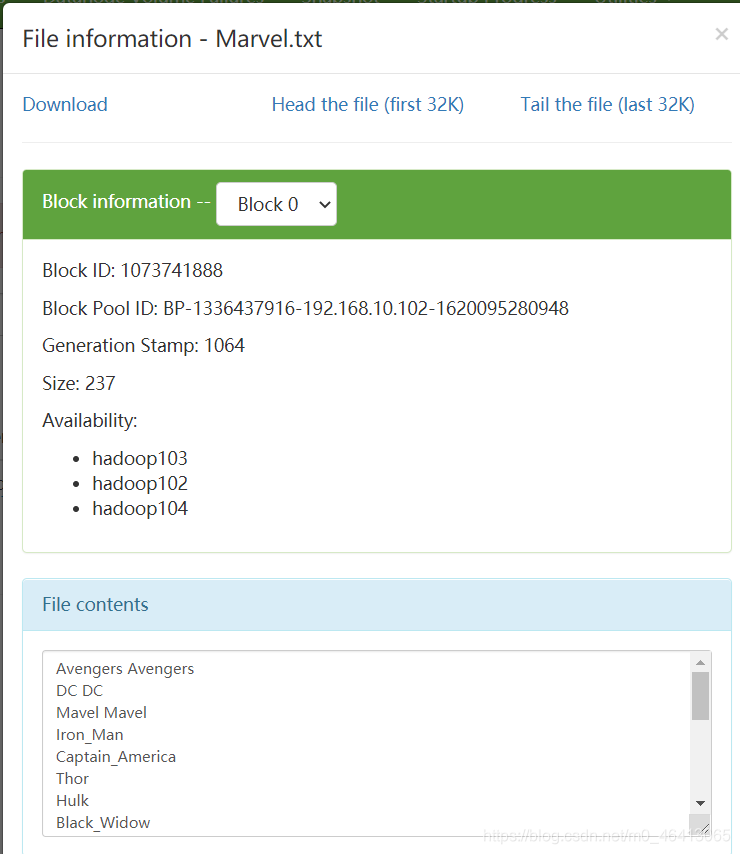
用户编写的程序分成三个部分:Mapper、Reducer 和 Driver。 1.Mapper阶段(1)用户自定义的Mapper要继承自己的父类 (2)Mapper的输入数据是KV对的形式(KV的类型可自定义) p.s. K是这一行的偏移量,V是这一行的内容。 (3)Mapper中的业务逻辑写在map()方法中 (1)用户自定义的Reducer要继承自己的父类 (2)Reducer的输入数据类型对应Mapper的输出数据类型,也是KV (3)Reducer的业务逻辑写在reduce()方法中 (4)ReduceTask进程对每一组相同k的组调用一次reduce()方法 3.Driver阶段相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的job对象 1.8 WordCount 案例实操 1.8.1 本地测试 1 ) 需求在给定的文本文件中统计输出每一个单词出现的总次数 (1)输入数据 创建一个文件夹 里面写上想要测试的数据 Avengers Avengers DC DC Mavel Mavel Iron_Man Captain_America Thor Hulk Black_Widow Hawkeye Black_Panther Spider_Man Doctor_Strange Ant_Man Vision Scarlet_Witch Winter_Soldier Loki Star_Lord Gamora Rocket_Raccoon Groot
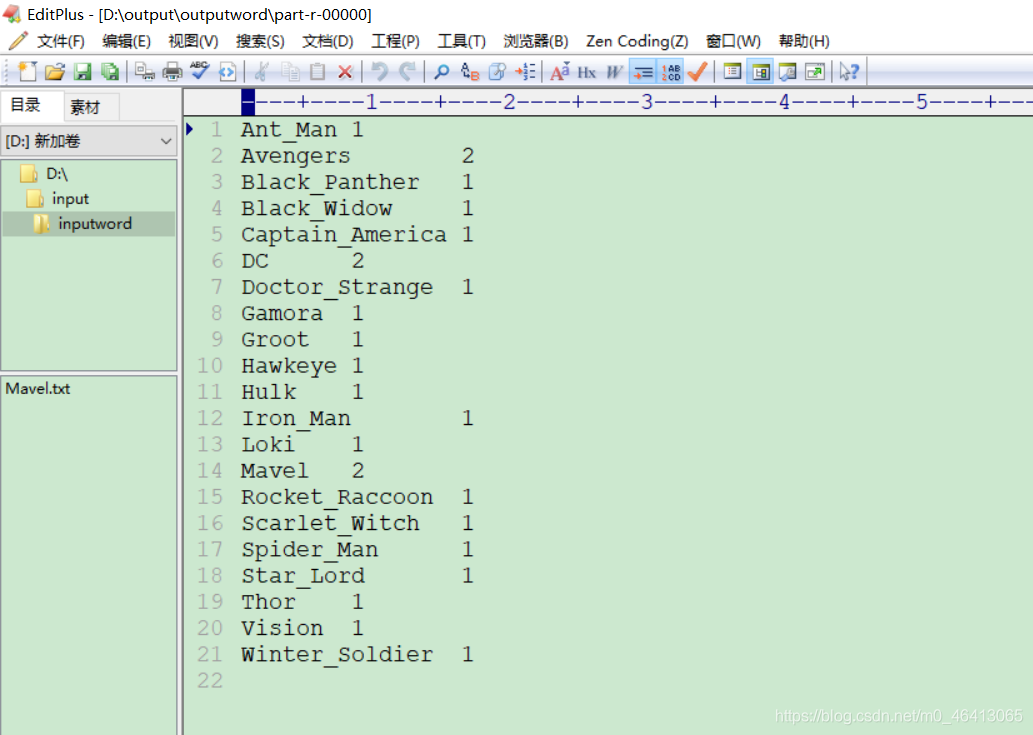
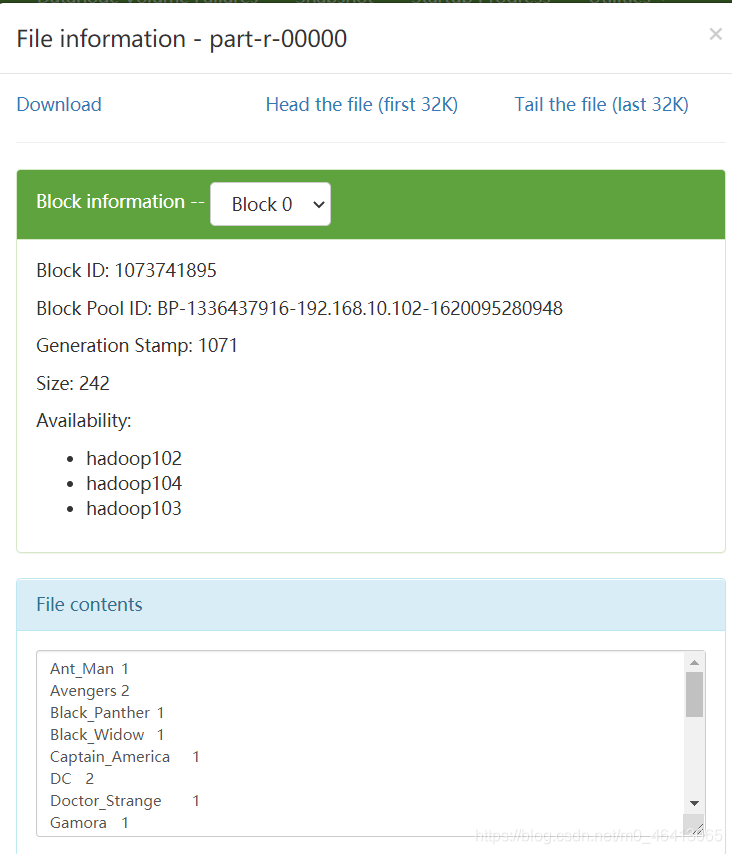
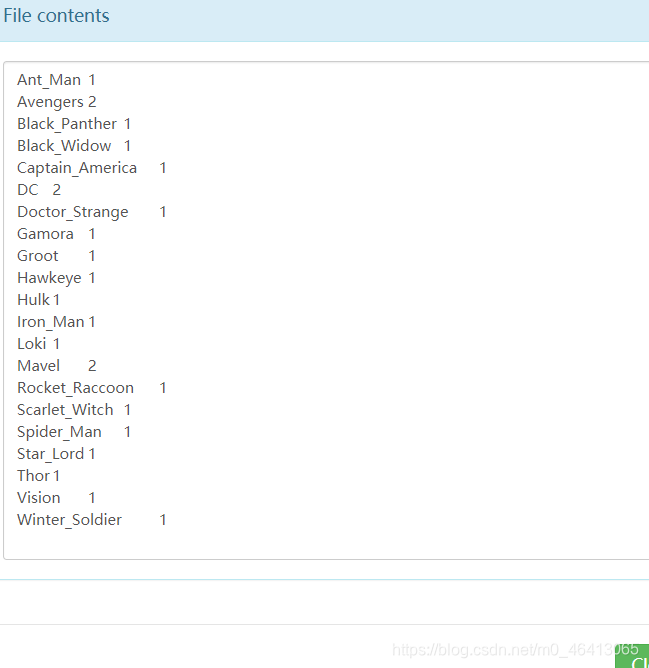
(2)期望输出数据 (涉及到输入的排序问题) Ant_Man 1 Avengers 2 Black_Panther 1 Black_Widow 1 Captain_America 1 DC 2 Doctor_Strange 1 Gamora 1 Groot 1 Hawkeye 1 Hulk 1 Iron_Man 1 Loki 1 Mavel 2 Rocket_Raccoon 1 Scarlet_Witch 1 Spider_Man 1 Star_Lord 1 Thor 1 Vision 1 Winter_Soldier 1 2 ) 需求分析按照 MapReduce 编程规范,分别编写 Mapper,Reducer,Driver。
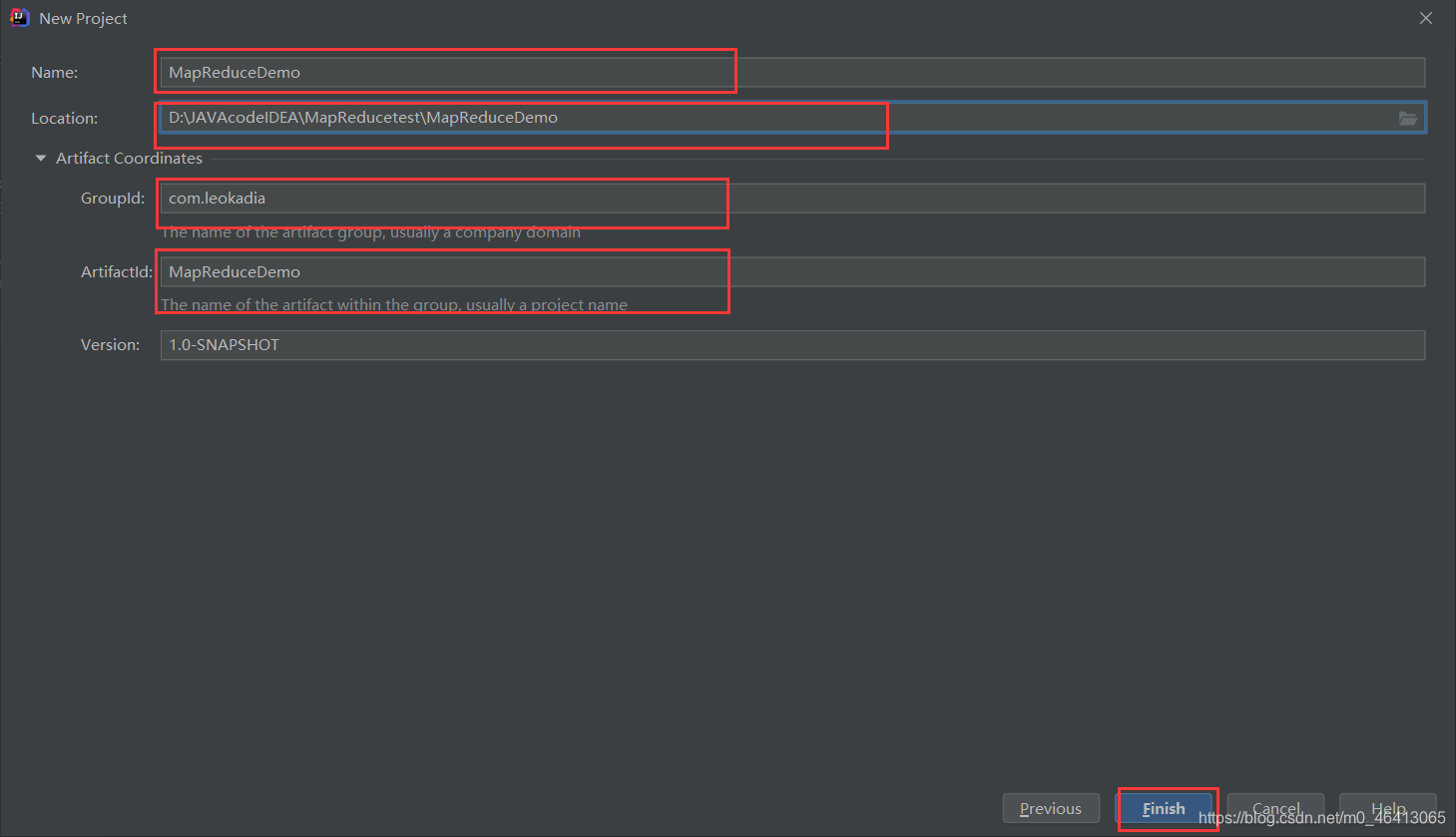
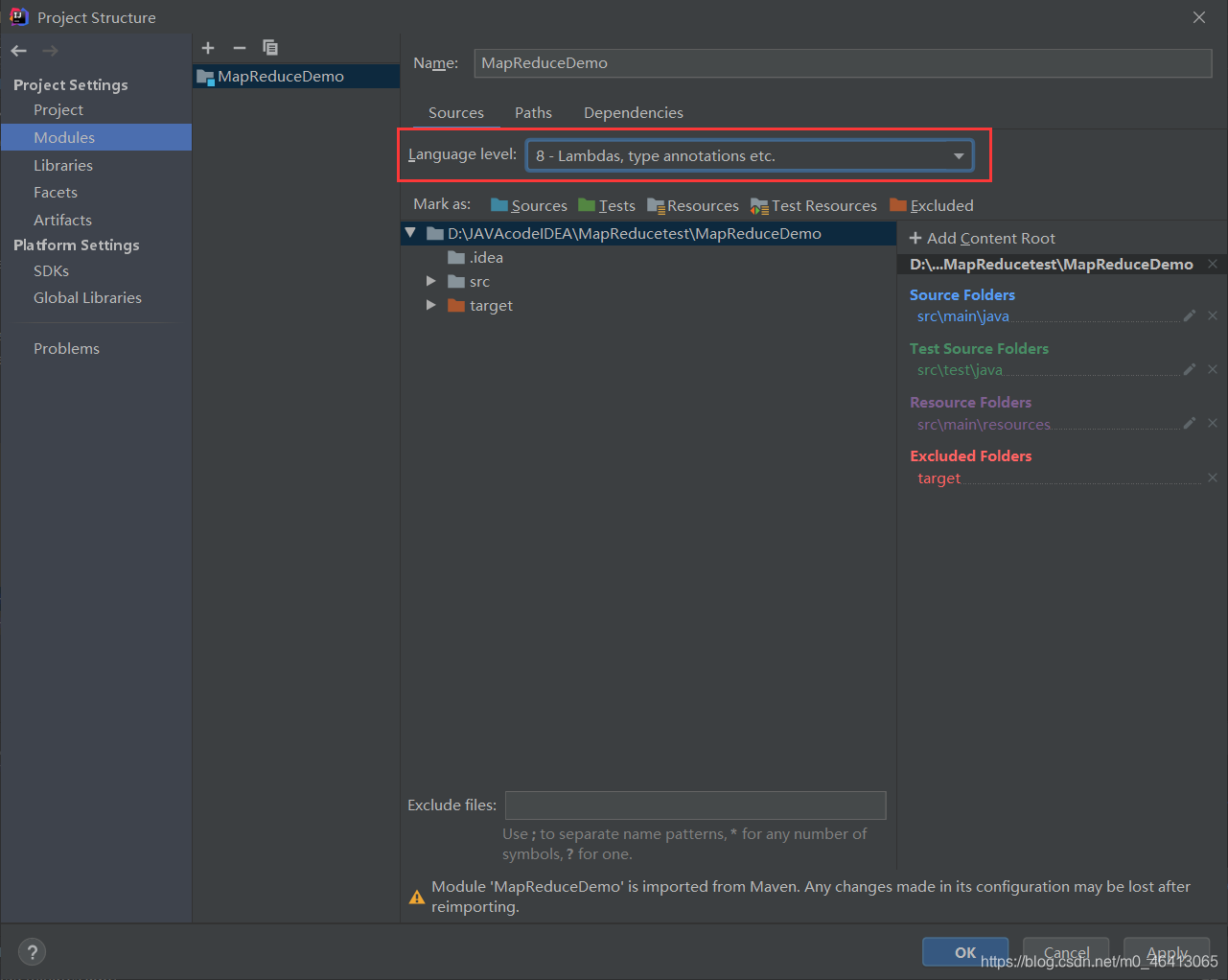
(1)创建 maven 工程,MapReduceDemo
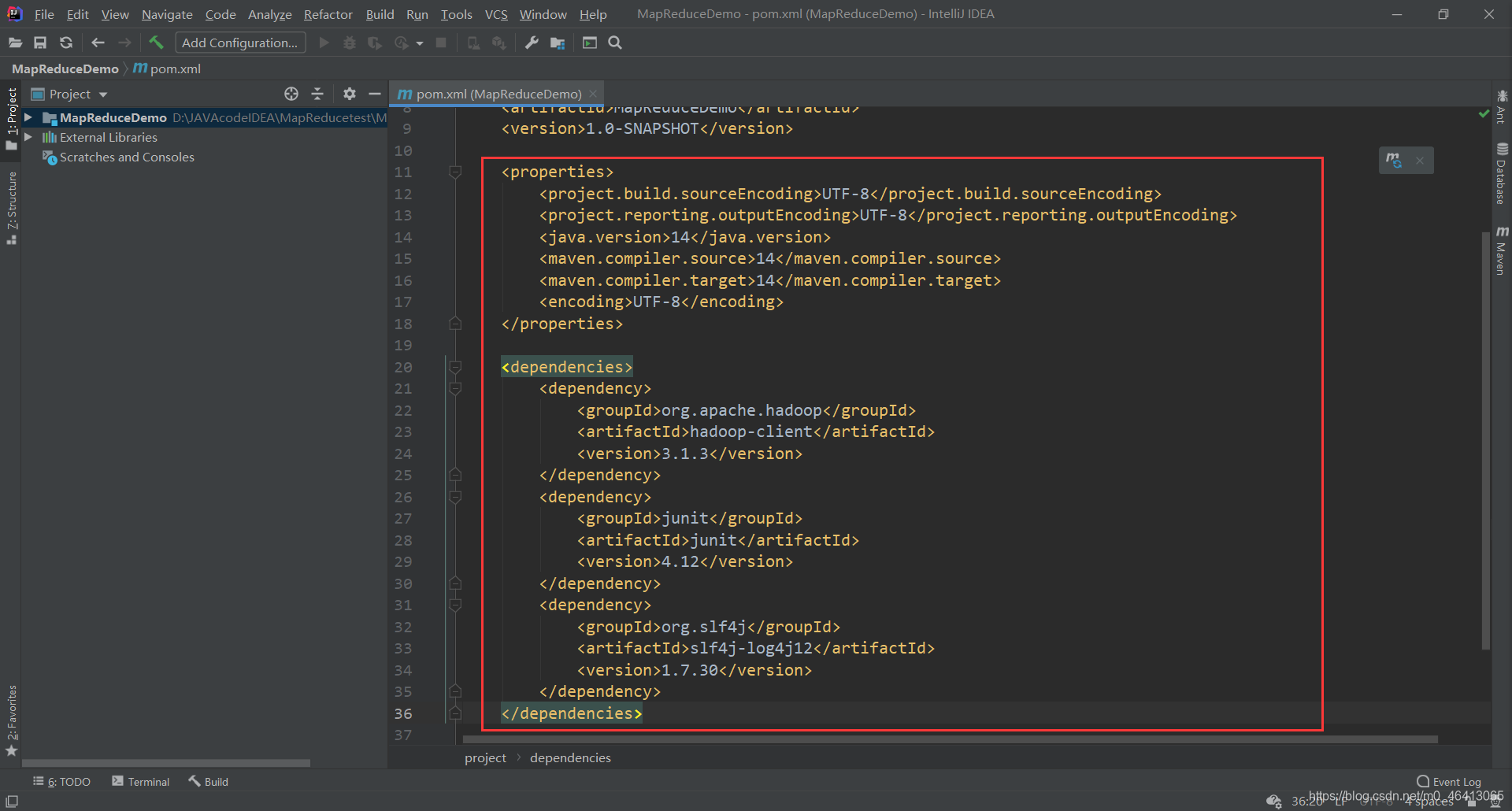
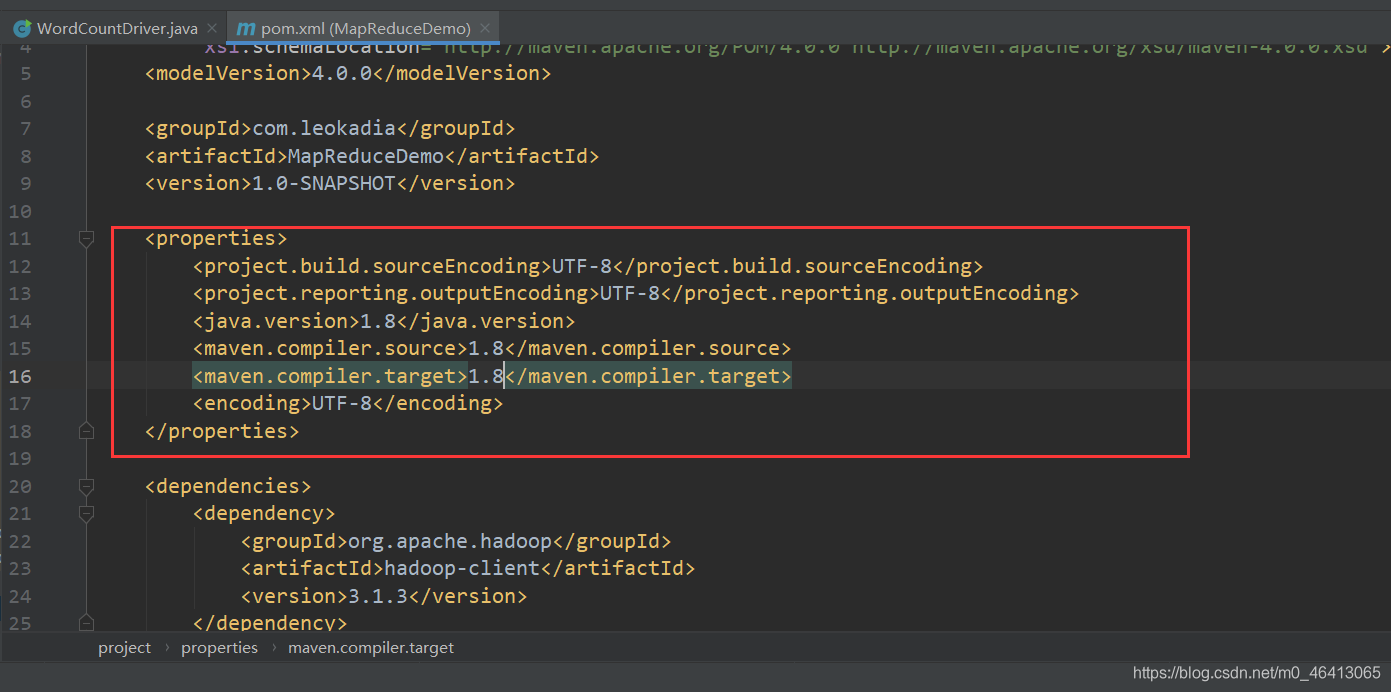
然后将相关java编译器配成自己的版本 相关内容参考 【Maven报错】Error:java: 不再支持源选项 5。请使用 6 或更高版本。(JDK14版成功解决) (2)在 pom.xml 文件中添加版本信息以及相关依赖 UTF-8 UTF-8 1.8 1.8 1.8 UTF-8 org.apache.hadoop hadoop-client 3.1.3 junit junit 4.12 org.slf4j slf4j-log4j12 1.7.30
(2)在项目的 src/main/resources 目录下,新建一个文件,命名为“log4j.properties”(打印相关日志)
(3)创建包名:com.leokadia.mapreduce.wordcount
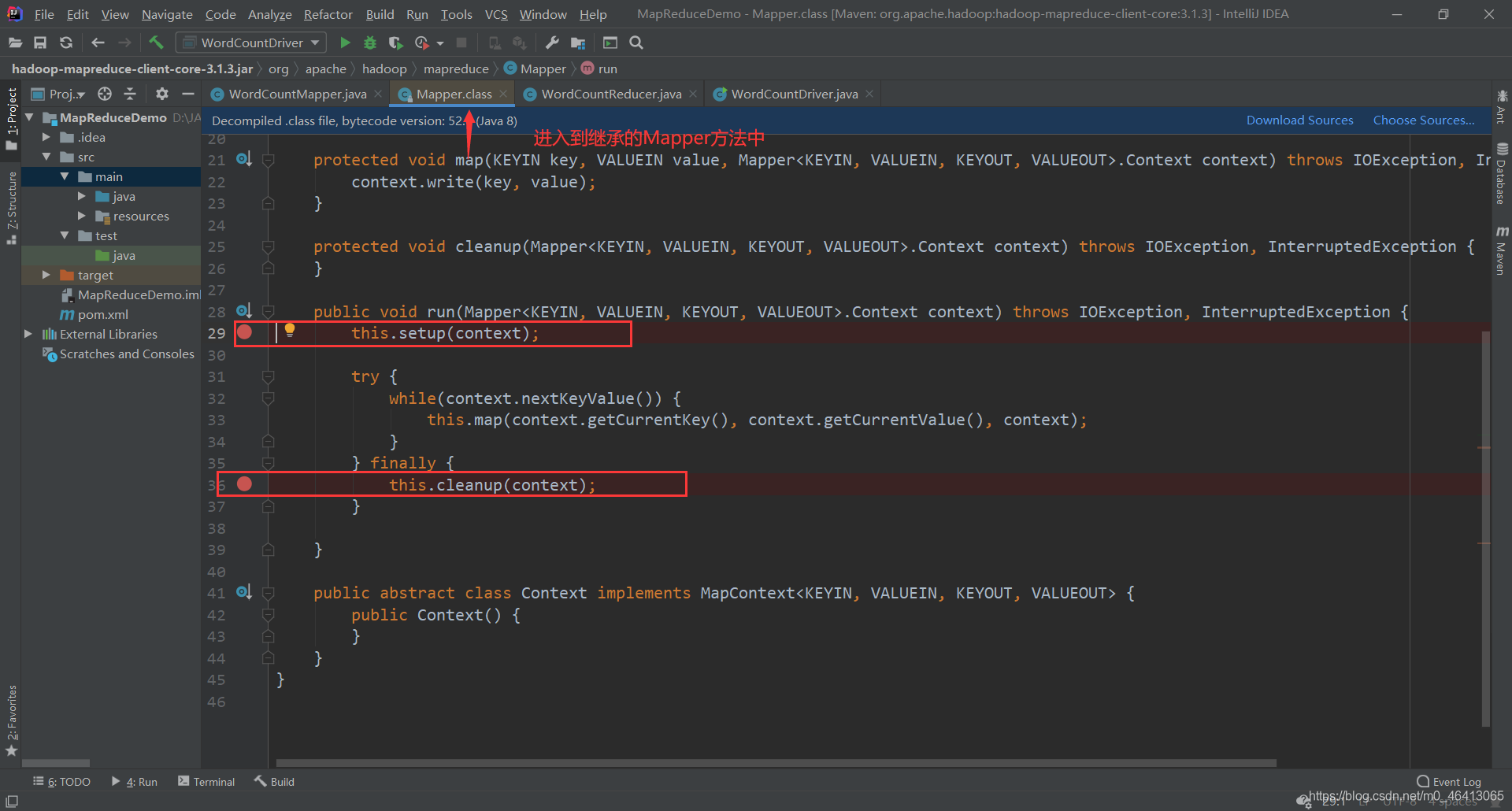
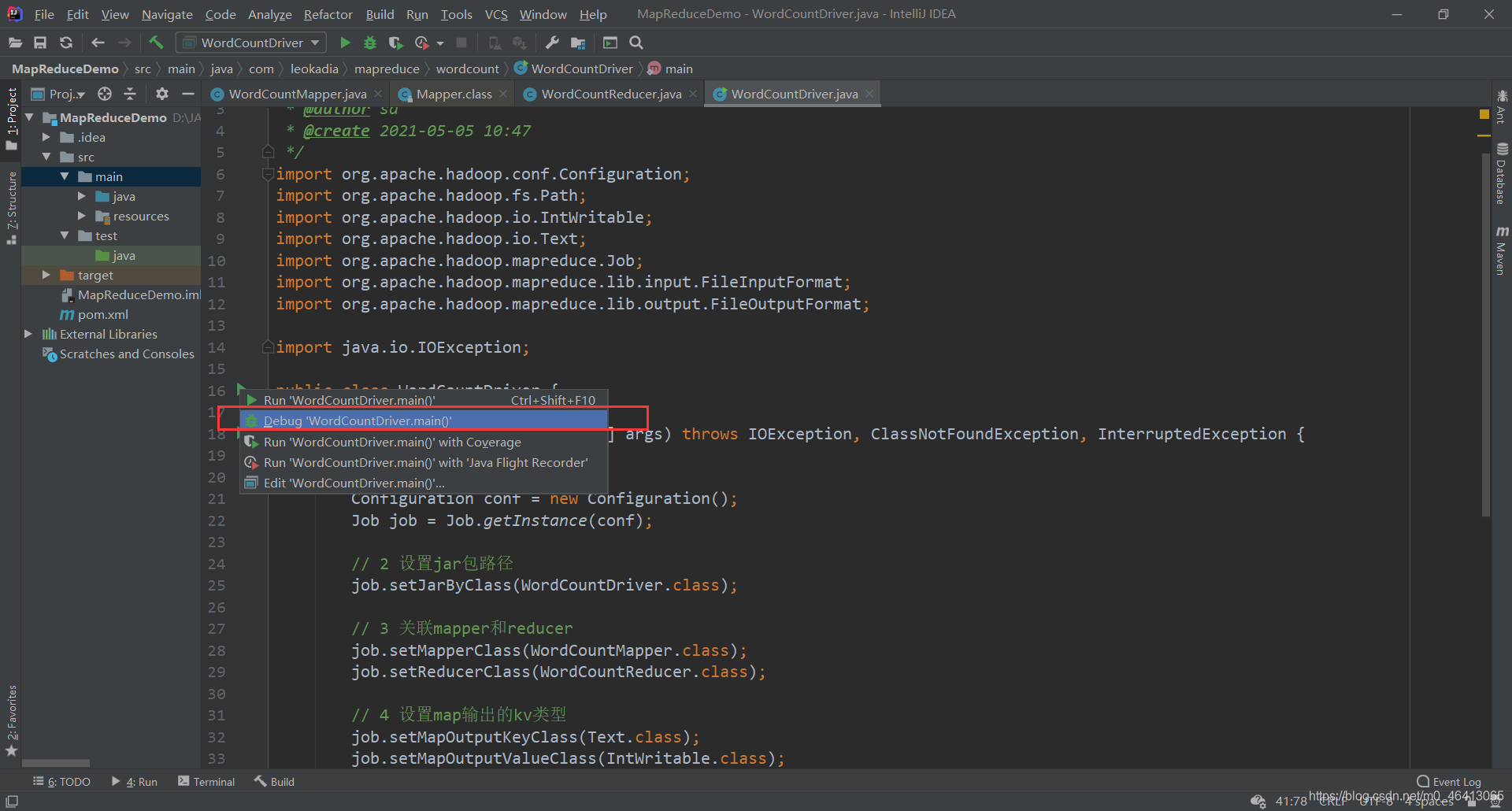
(1)需要首先配置好 HADOOP_HOME 变量以及 Windows 运行依赖 (2)在 IDEA 上运行程序 运行: 在以下几个地方打好断点 开始Debug
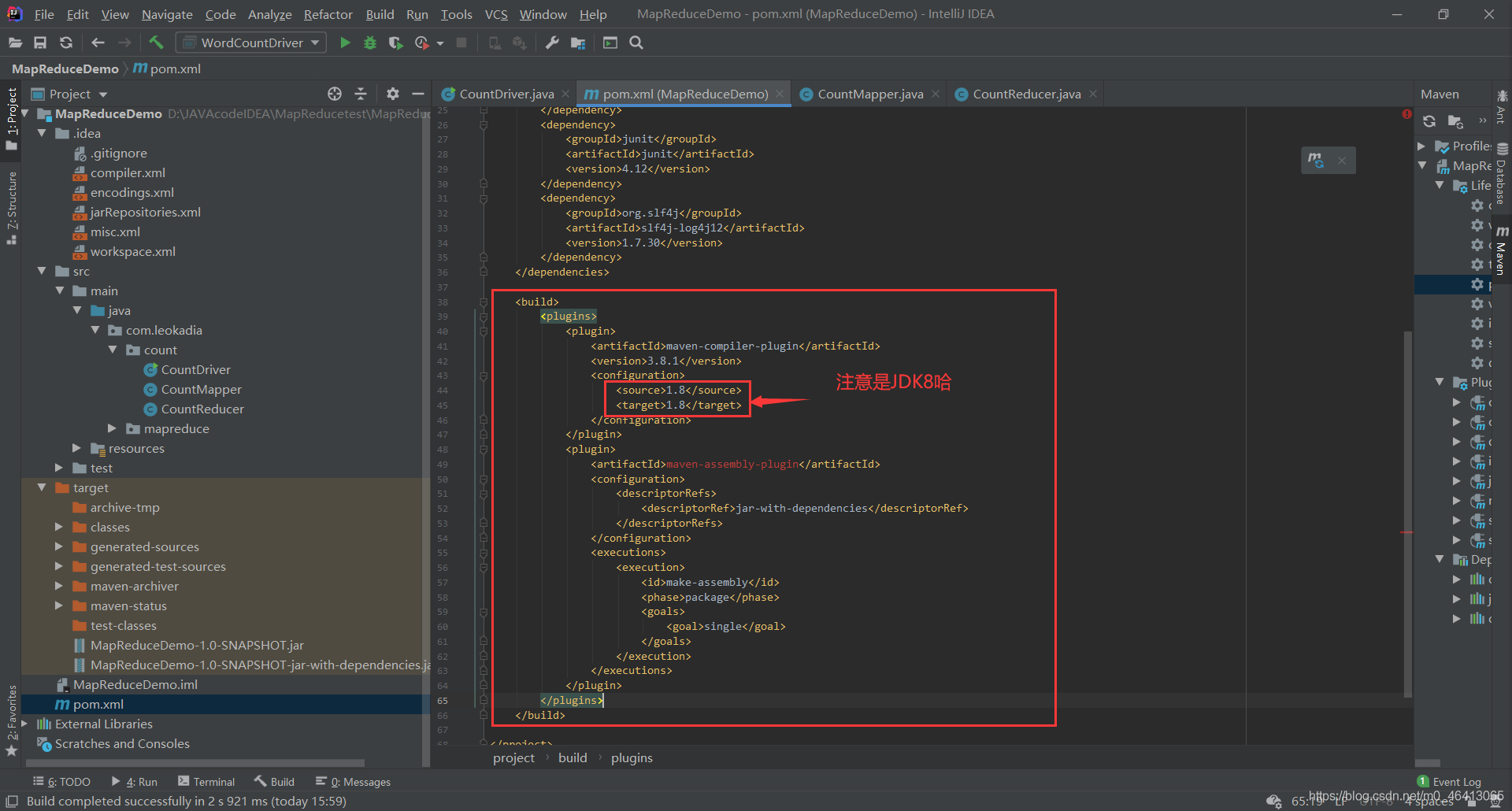
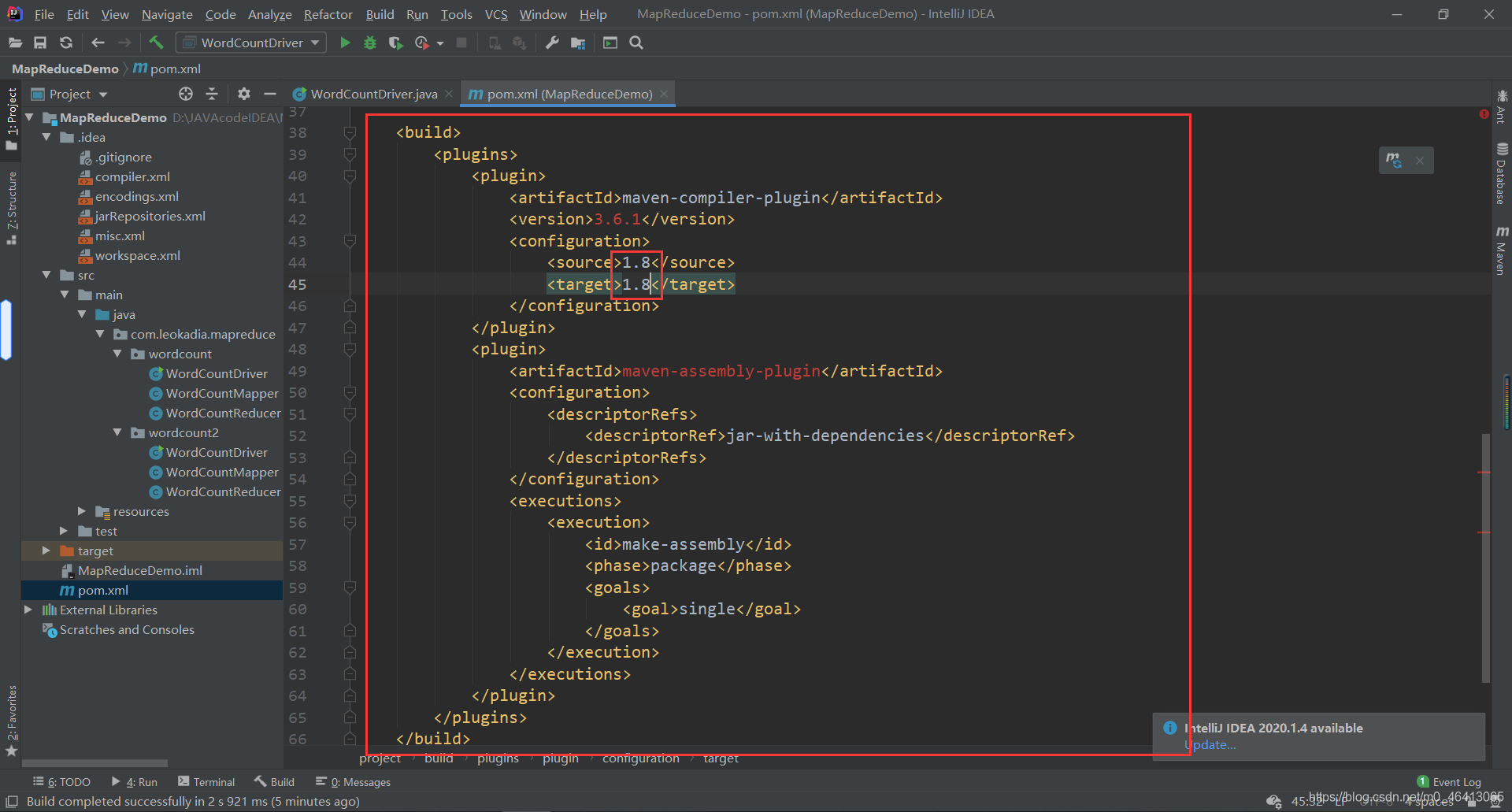
刚刚上面的代码是在本地运行的,是通过下载了hadoop相关的依赖,运用本地模式运行的 这样肯定是不行的,因为未来生产环境中,我们肯定是要在linux虚拟机上去运行 集群上测试 (1)用 maven 打 jar 包,需要添加的打包插件依赖将下面的代码放在之前配置的依赖后面 maven-compiler-plugin 3.6.1 1.8 1.8 maven-assembly-plugin jar-with-dependencies make-assembly package single
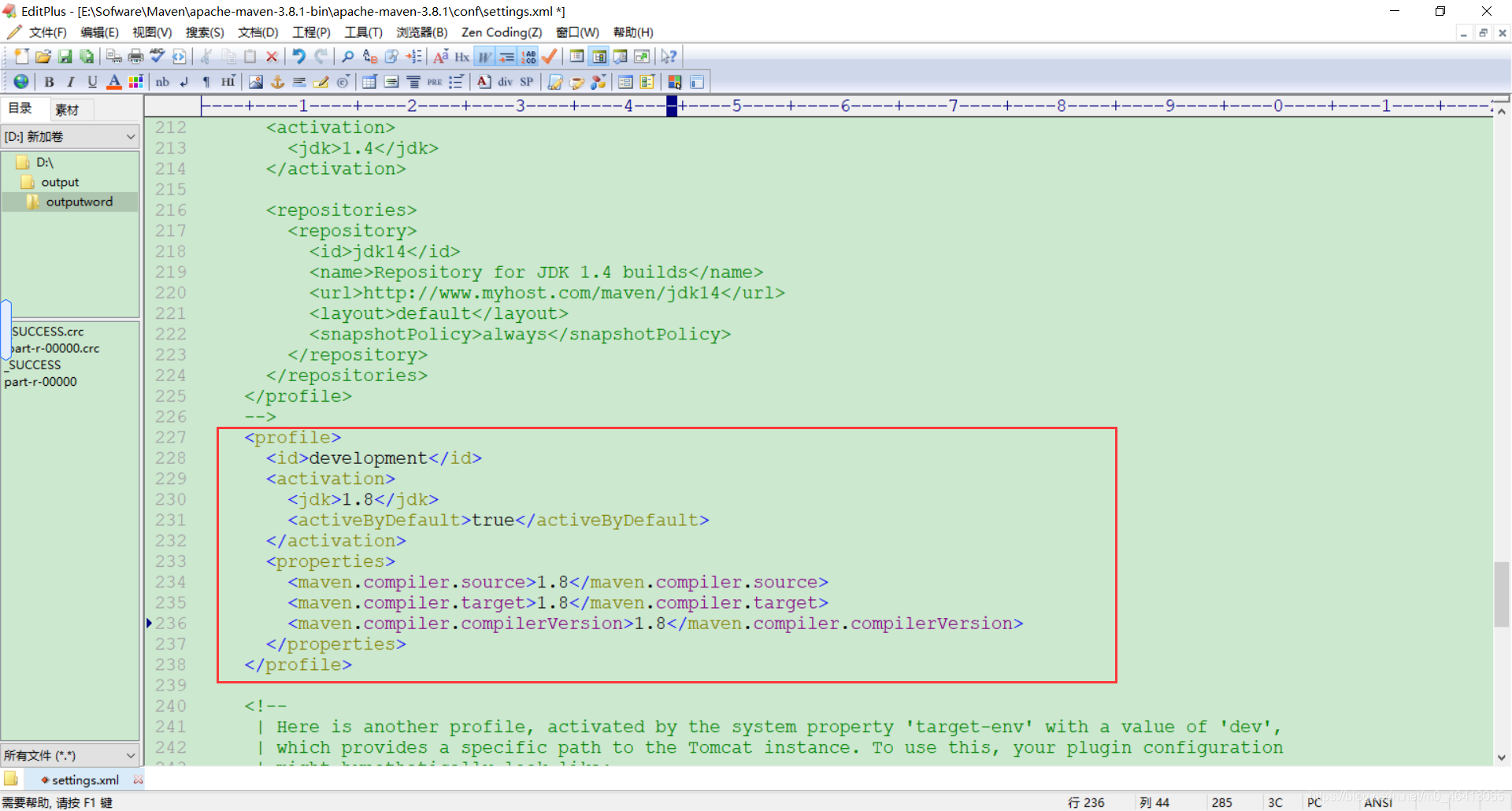
注意:博主原来的配置是14后面你们会发现14其实hadoop不支持,所以应该配置为JDK8,我将放的代码都改成了8的配置哈。 注意:如果工程上显示红叉。在项目上右键->maven->Reimport 刷新即可。 (2)将程序打成 jar 包
将上面6kb的复制到桌面并改名 我们再创建一个wordcount2包,跟wordcount内容一致,就将输入输出路径修改了一下 将新的包按上面的操作更名wc.jar (4)启动 Hadoop 集群[leokadia@hadoop102 mapreduce]$ myhadoop.sh start
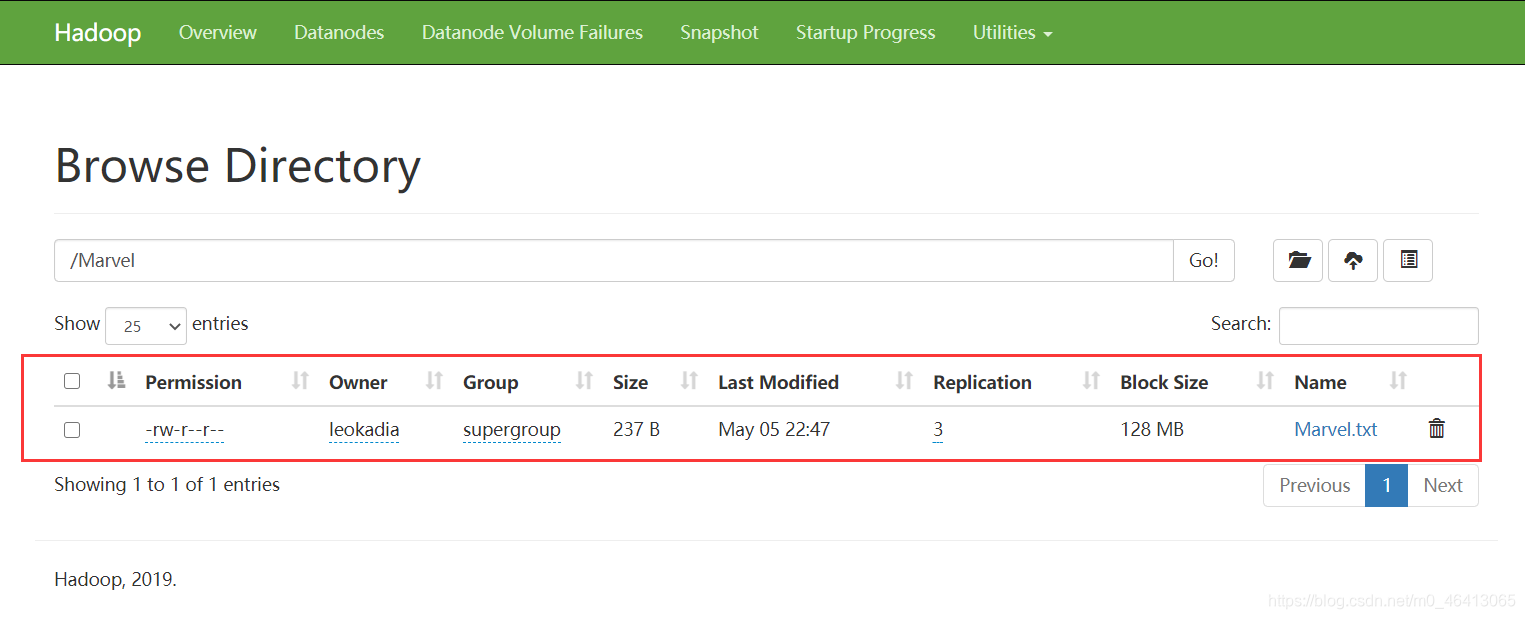
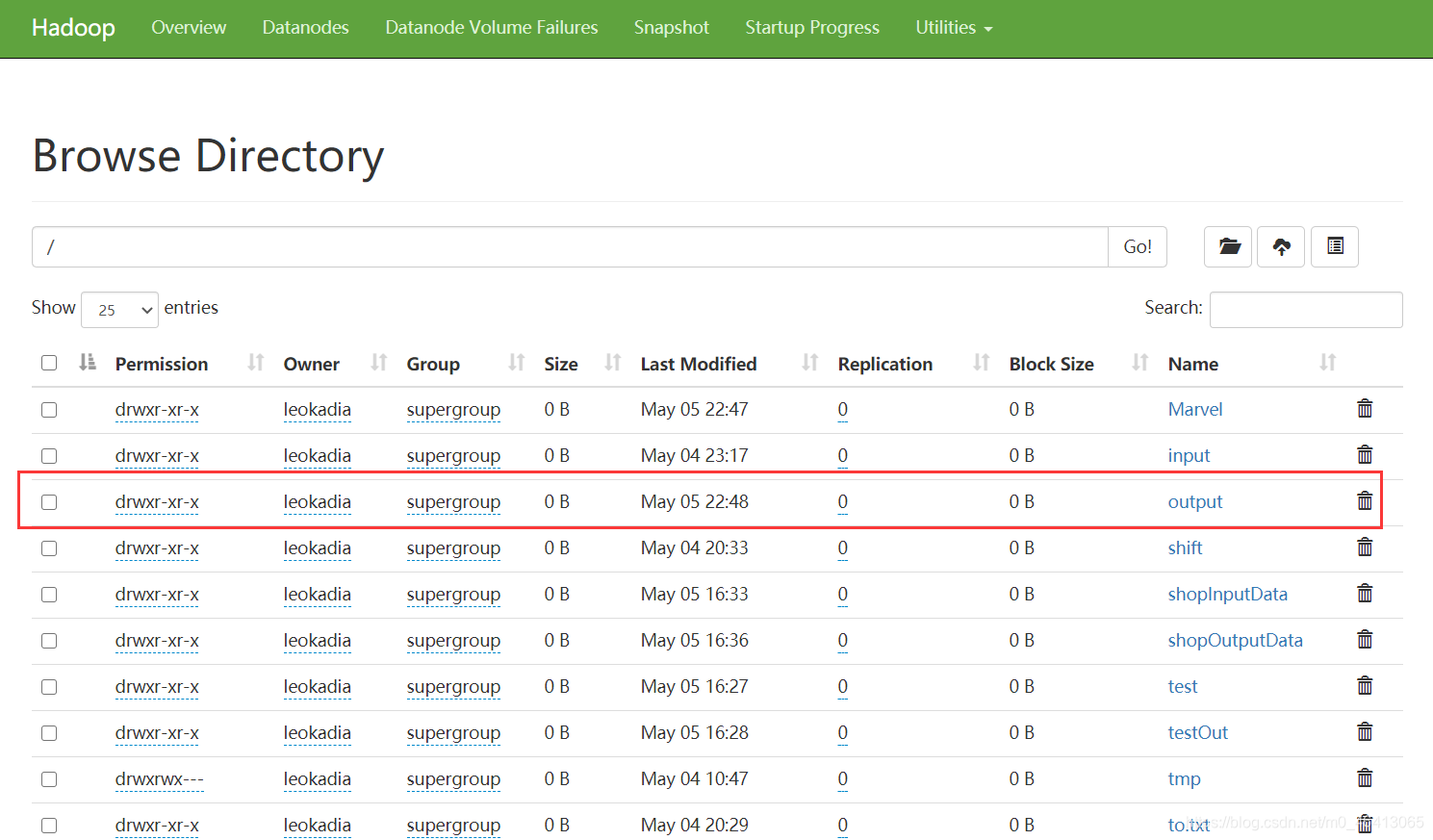
先在HDFS集群中设置刚刚要wordcount的源文件 在集群中建一个Marvel文件夹 在文件夹中上传我们之前要wordcount的Marvel.txt源文件
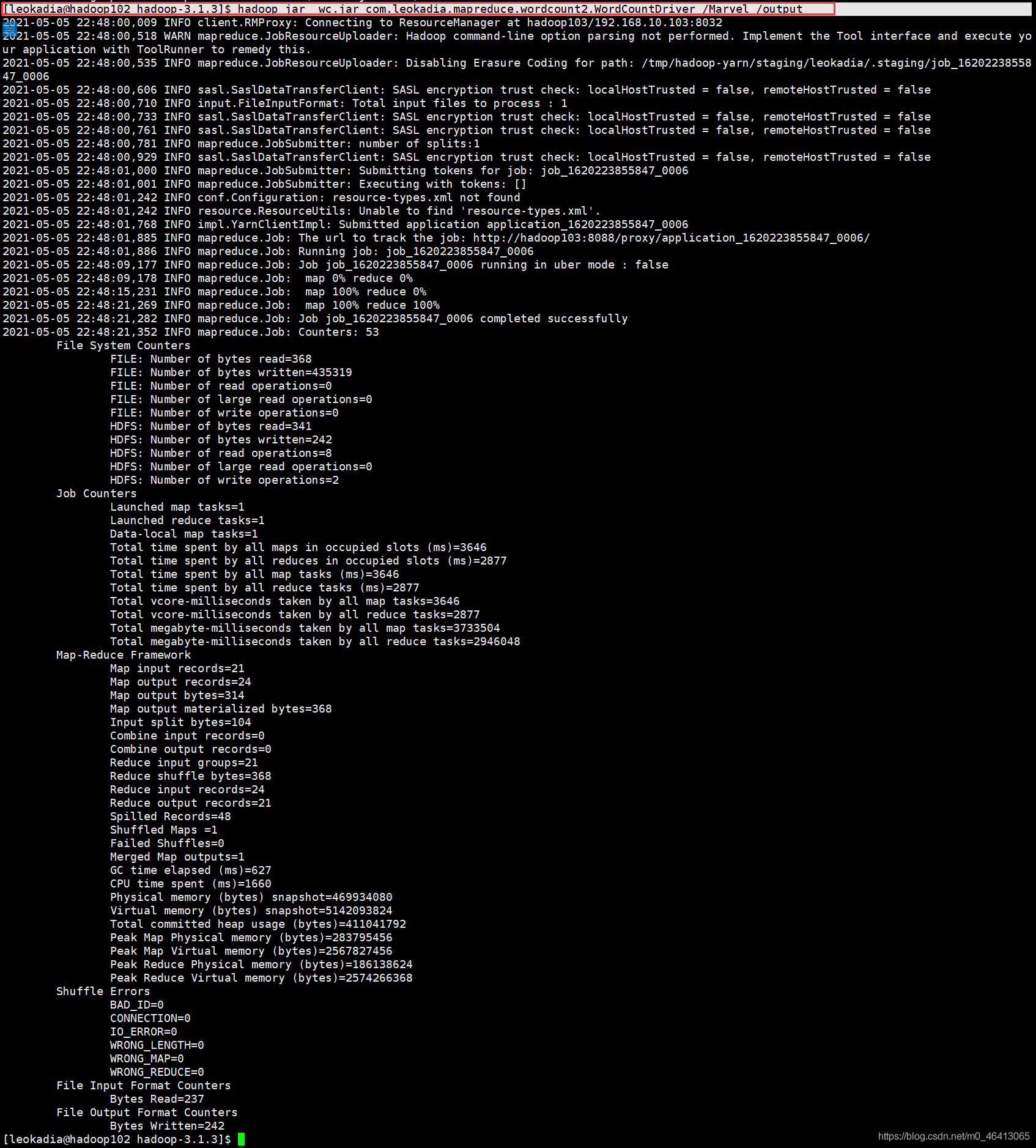
[leokadia@hadoop102 hadoop-3.1.3]$ hadoop jar wc.jar com.leokadia.mapreduce.wordcount2.WordCountDriver /user/leokadia/Marvel /user/leokadia/output 你以为输入以上代码就是最后一步大功告成了? 不好意思,博主的java本地版本与hadoop的版本不兼容 博主本地装的14,当时在hadoop里面配置的8 博主本地的java版本
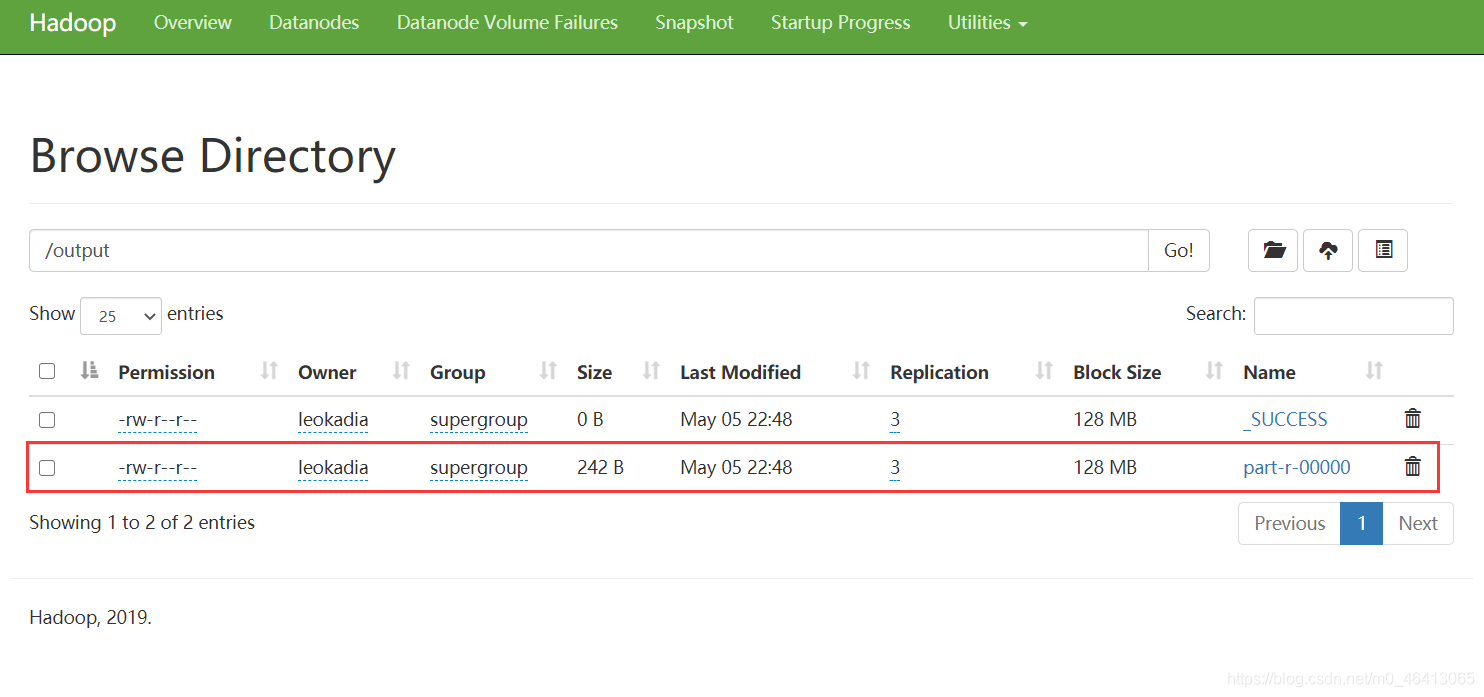
然后再重新生成jar包,导入jar包到集群,再重新运行程序 [leokadia@hadoop102 hadoop-3.1.3]$ hadoop jar wc.jar com.leokadia.mapreduce.wordcount2.WordCountDriver /Marvel /output |

 下载下来是一个jar包:
下载下来是一个jar包:  如何查看里面的代码程序呢? 可以从网上下载一个反编译工具:
如何查看里面的代码程序呢? 可以从网上下载一个反编译工具:  点击jd-gui.exe运行,显示如下界面:
点击jd-gui.exe运行,显示如下界面: 将桌面上的源码jar包拖拽过来:
将桌面上的源码jar包拖拽过来: 
 打开其中官方WordCount程序
打开其中官方WordCount程序  详细剖析其中代码
详细剖析其中代码 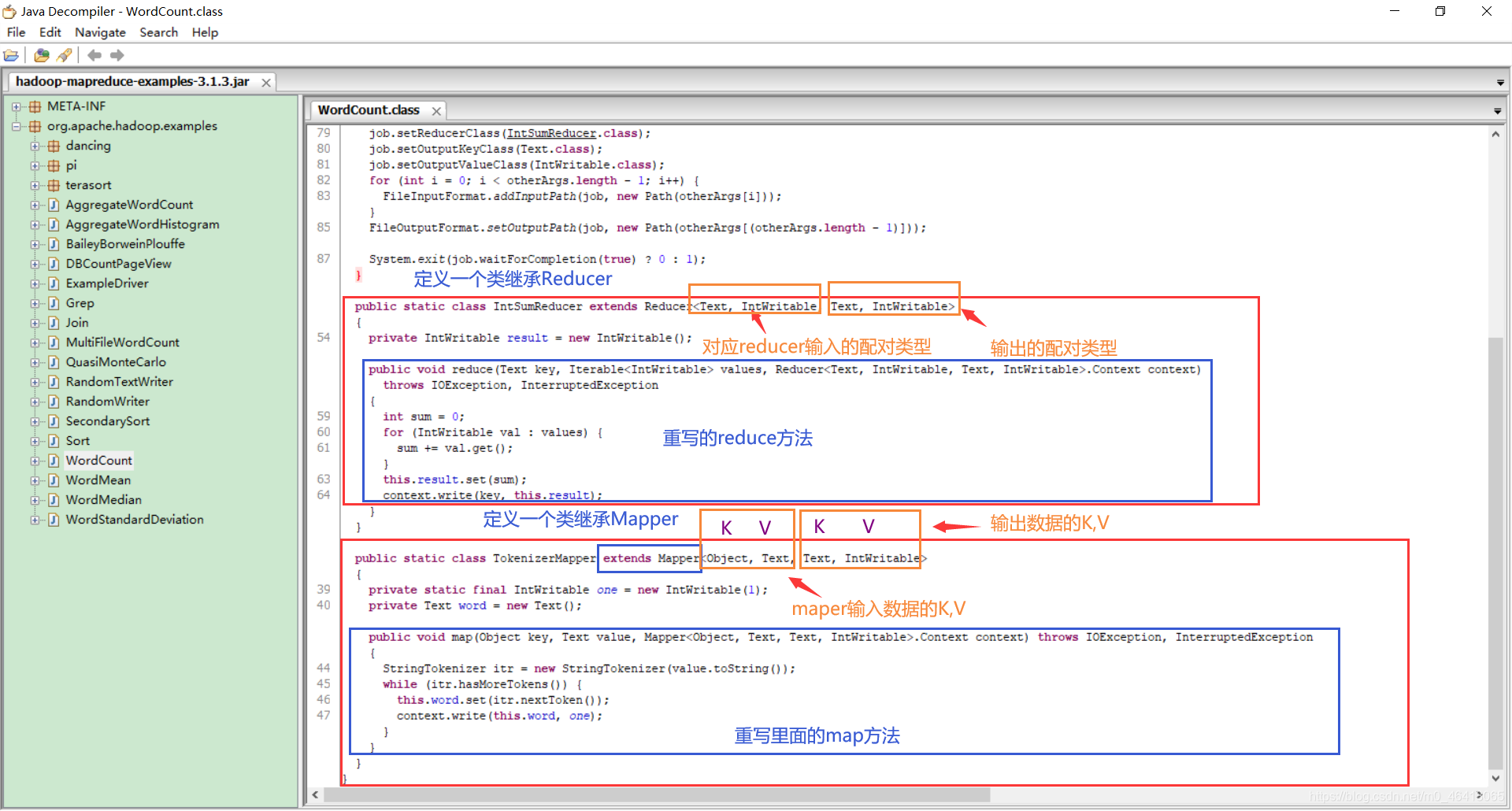


 (4)Mapper的输出数据是KV对的形式(KV的类型可自定义) (5)map()方法(MapTask进程)对每一个调用一次
(4)Mapper的输出数据是KV对的形式(KV的类型可自定义) (5)map()方法(MapTask进程)对每一个调用一次



 按照之前的修改成自己的Maven仓库,相关内容可参考: HDFS的API环境准备小知识——Maven 安装与配置
按照之前的修改成自己的Maven仓库,相关内容可参考: HDFS的API环境准备小知识——Maven 安装与配置 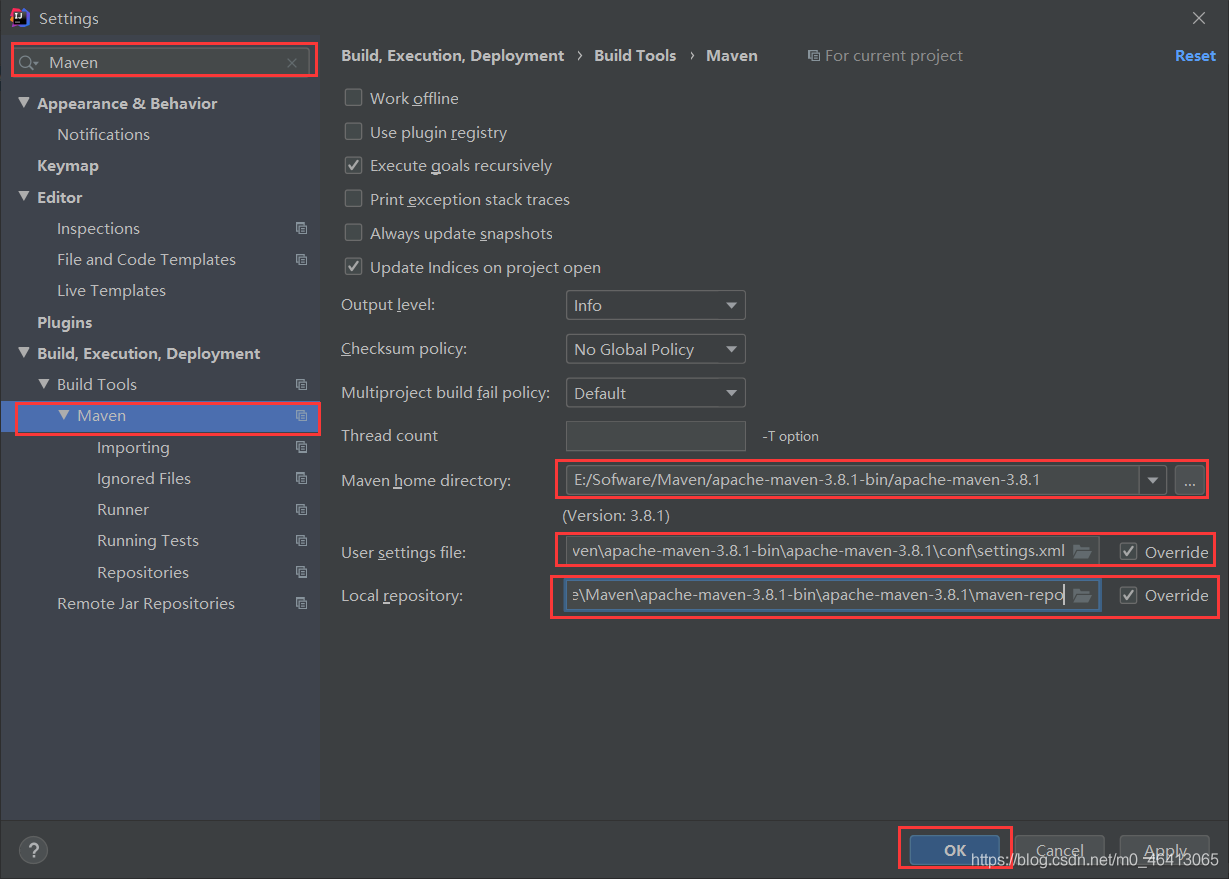
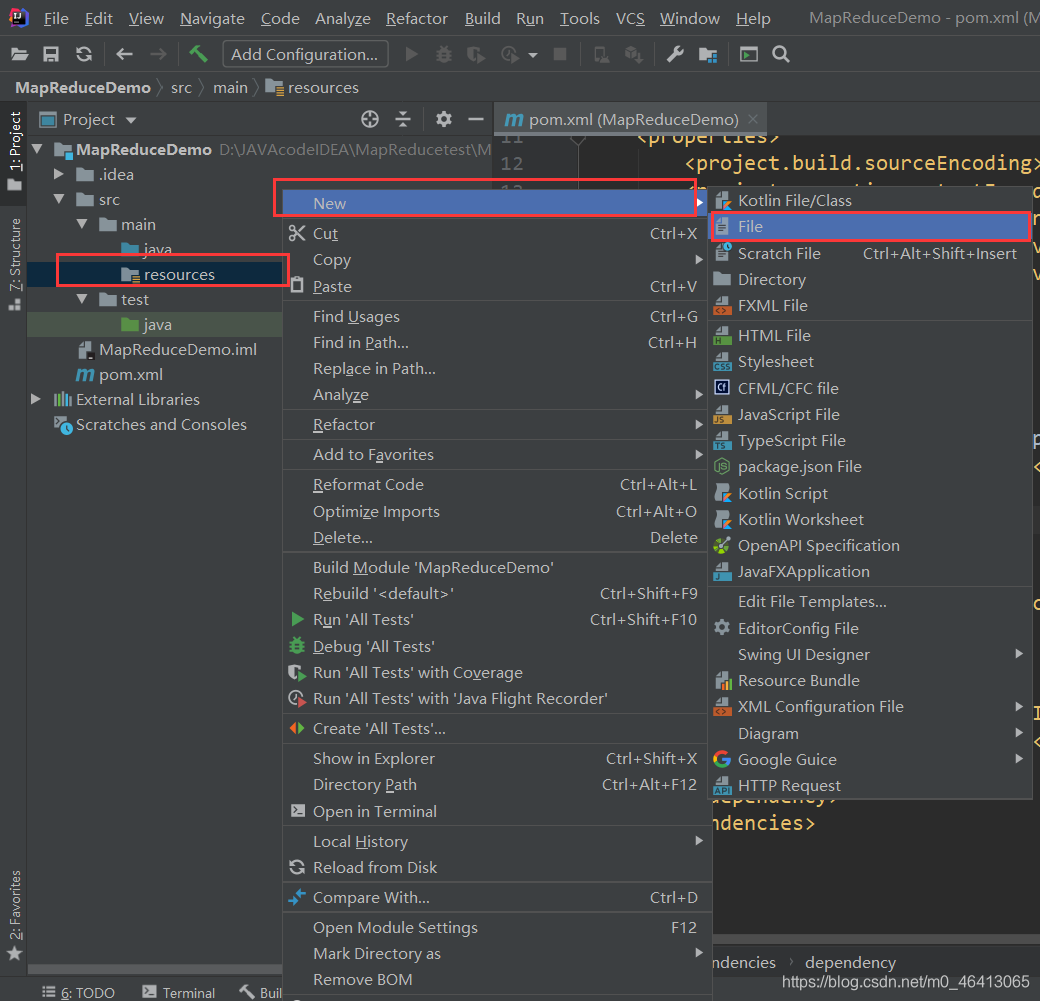
 在文件中填入:
在文件中填入: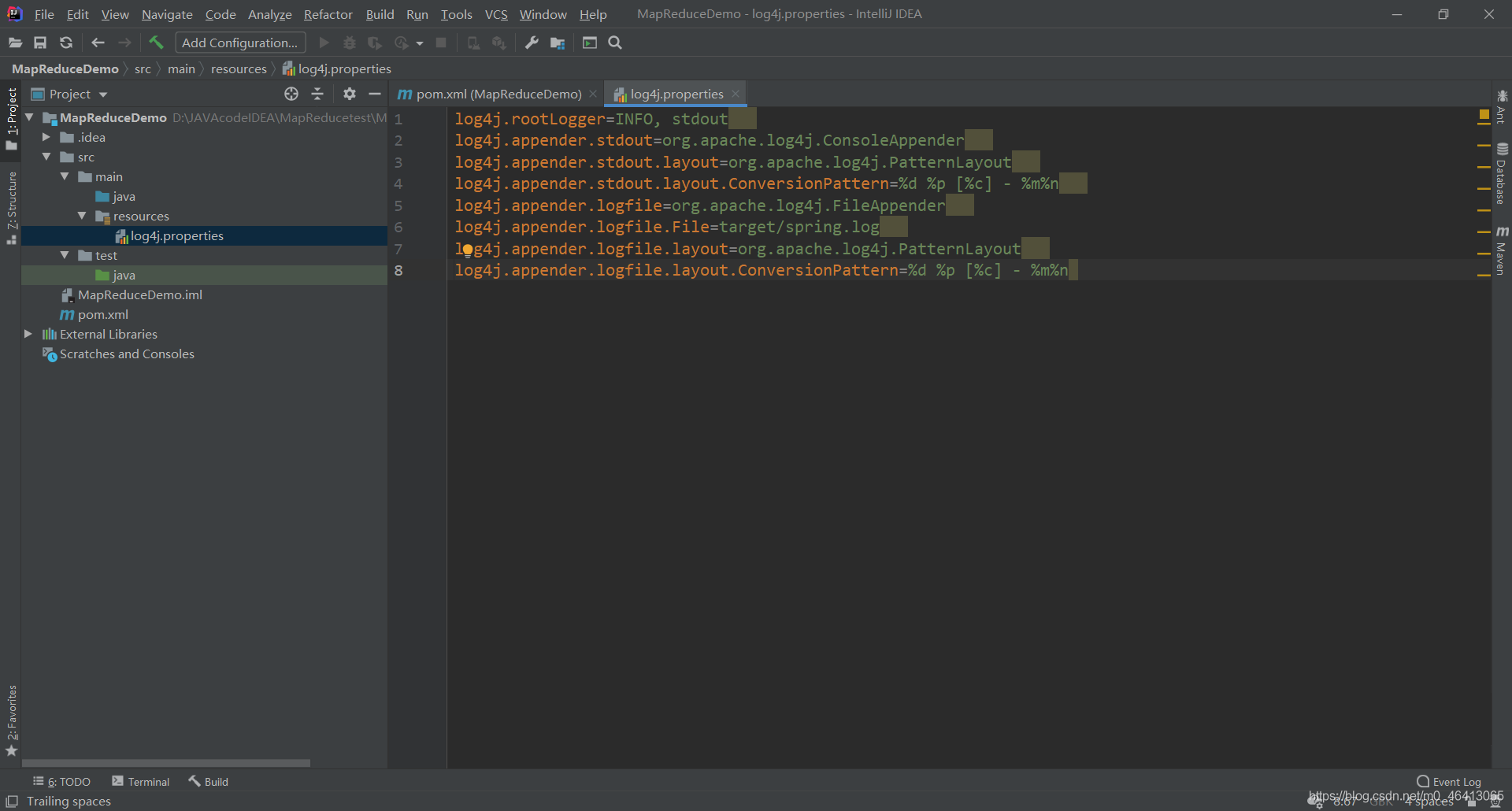
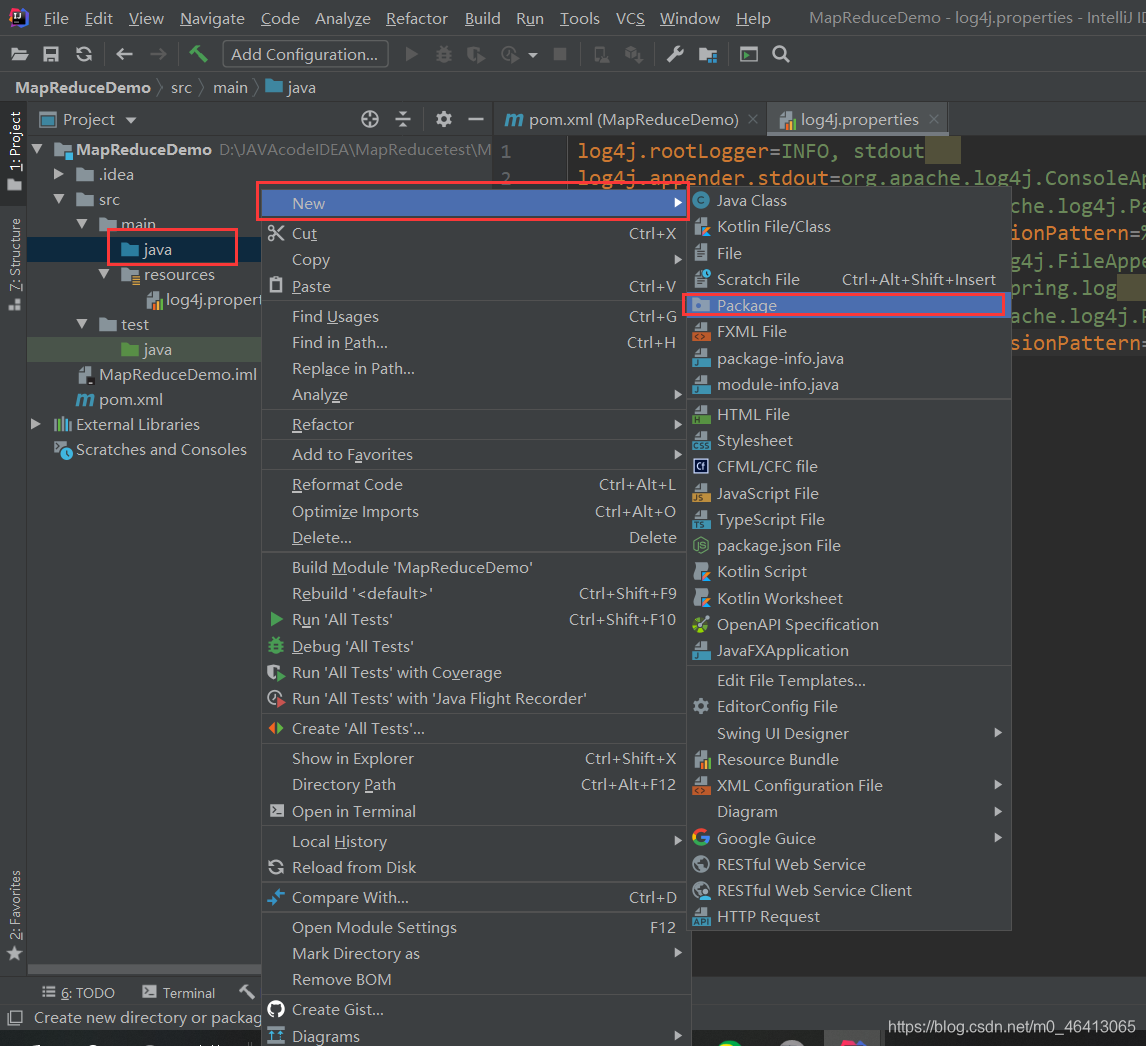
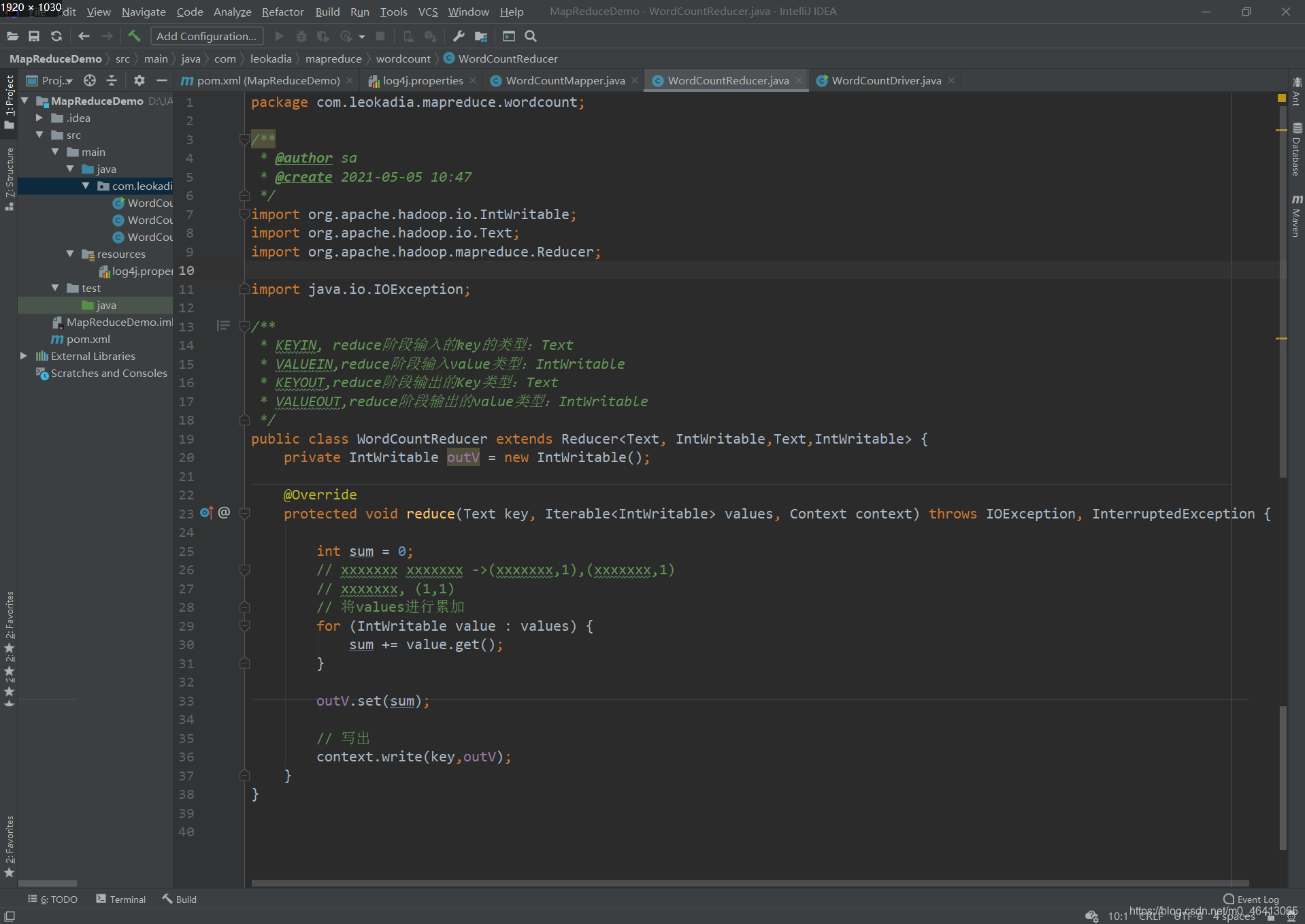
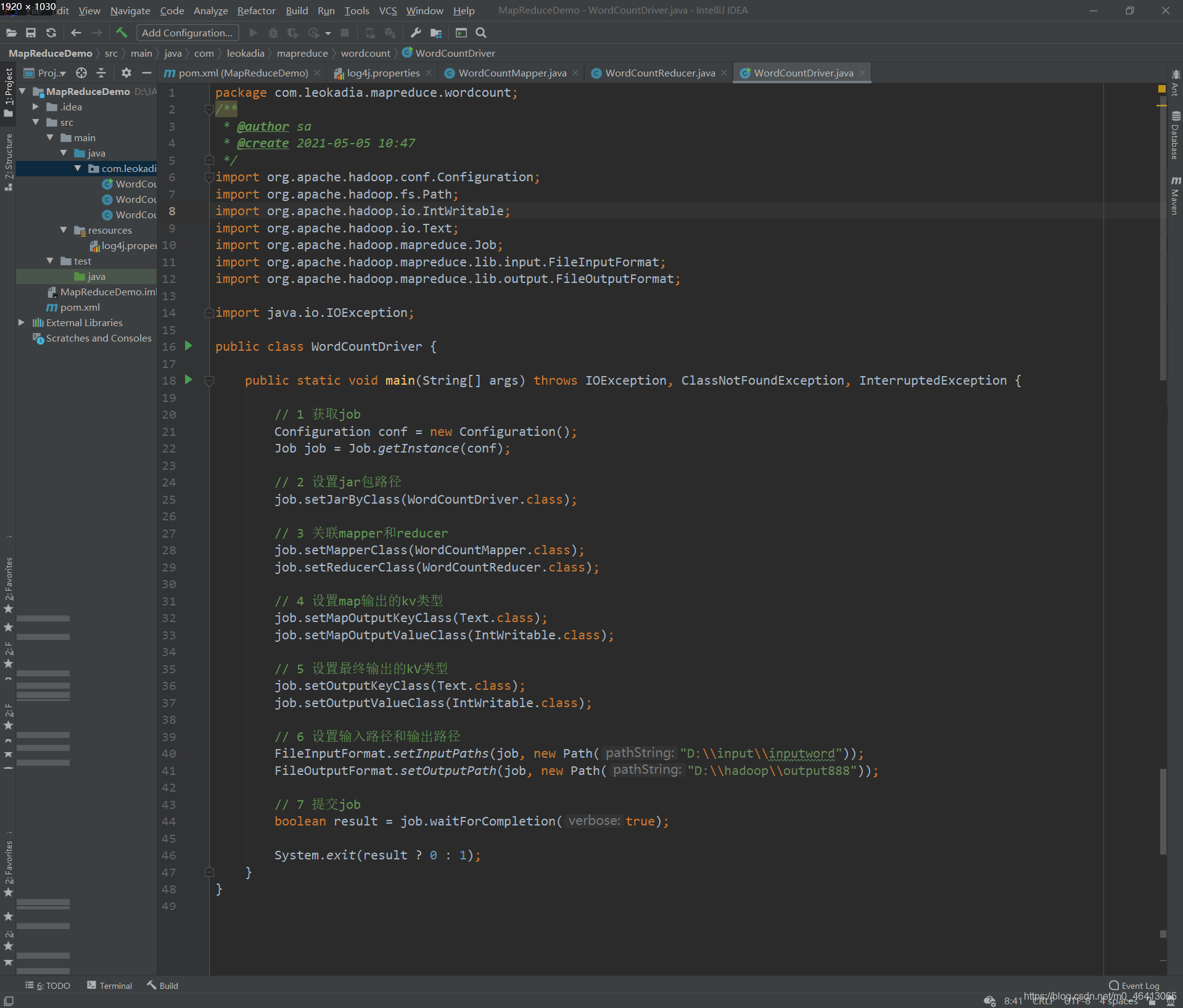
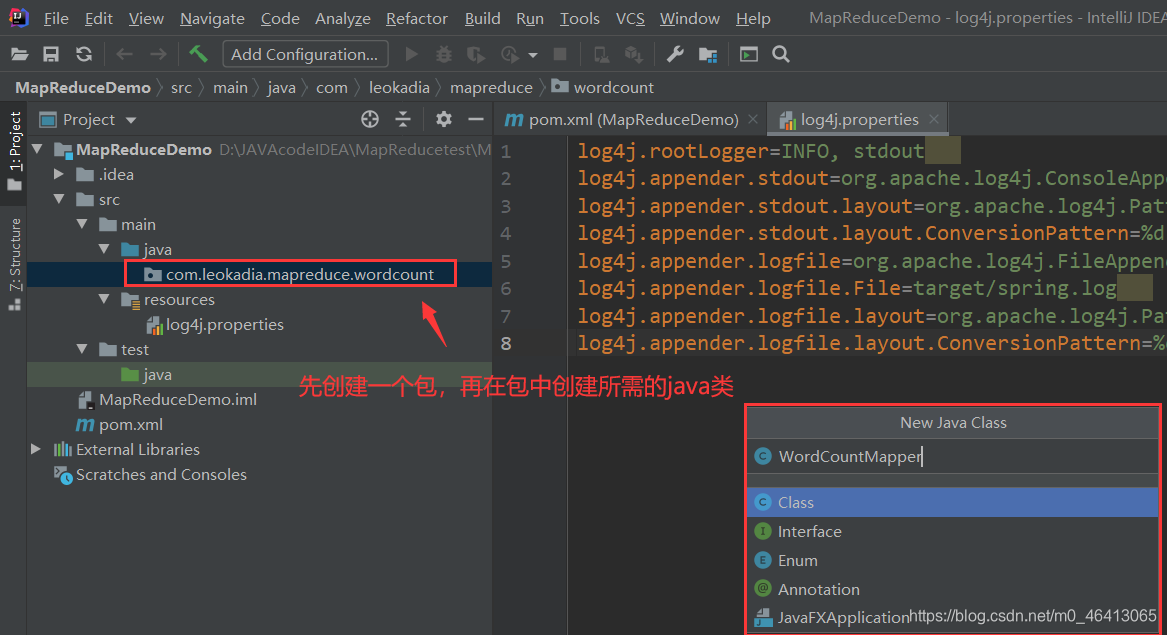 创建三个类
创建三个类 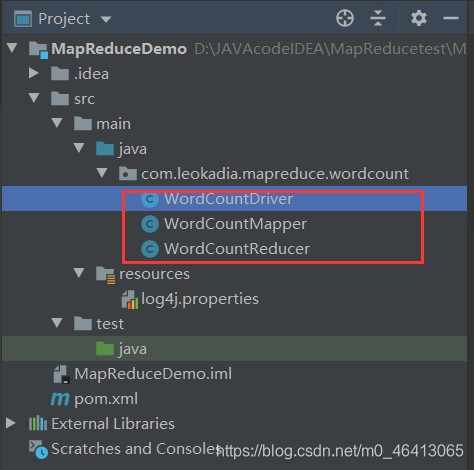
 注意:此时如果再运行一遍,会报错
注意:此时如果再运行一遍,会报错 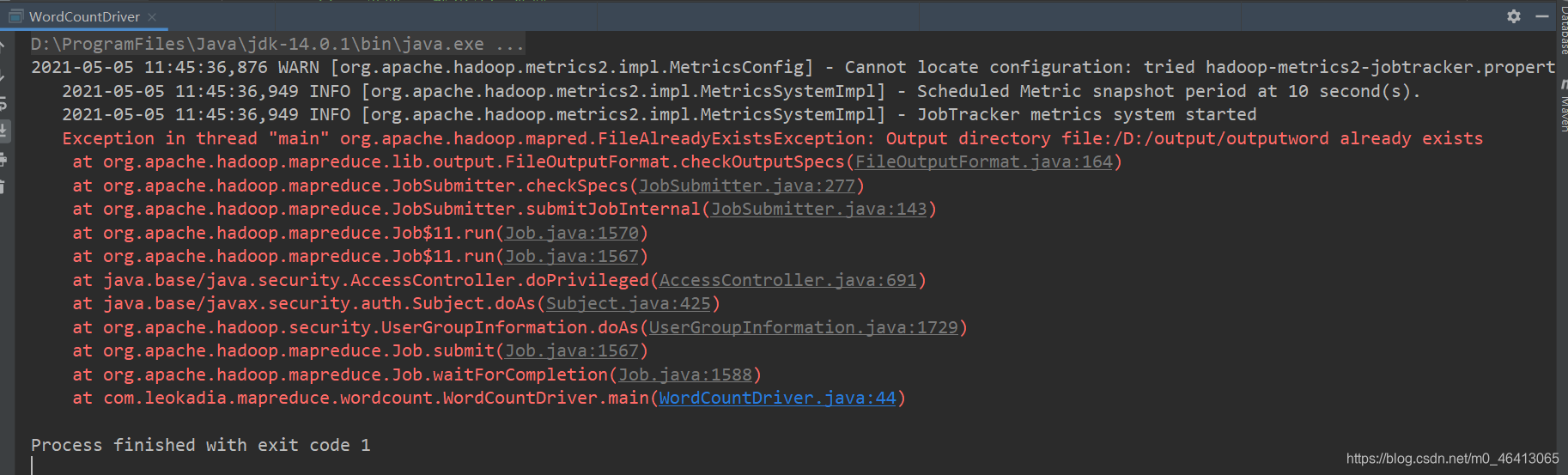 在mapreduce中,如果输出路径存在会报错
在mapreduce中,如果输出路径存在会报错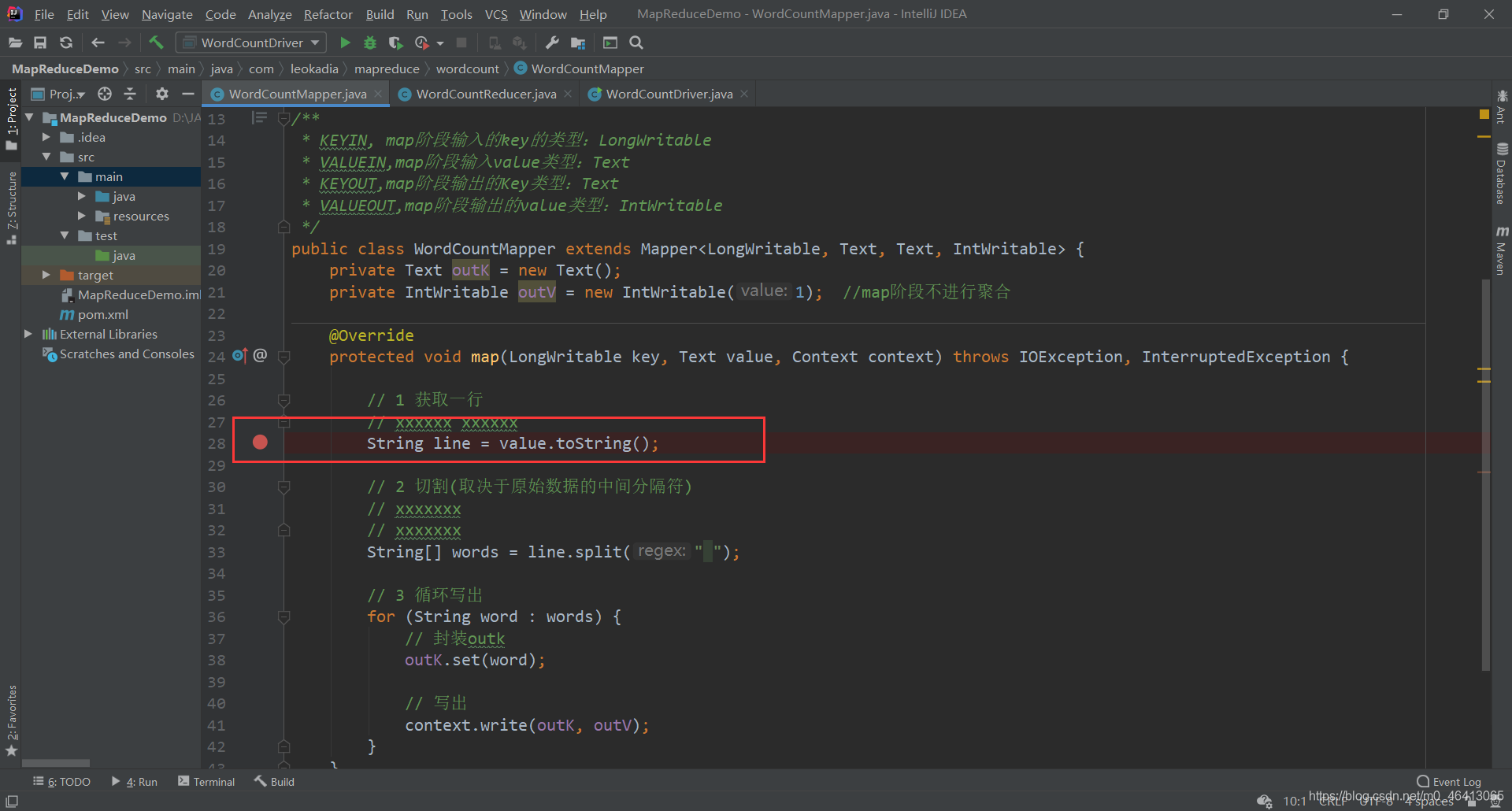
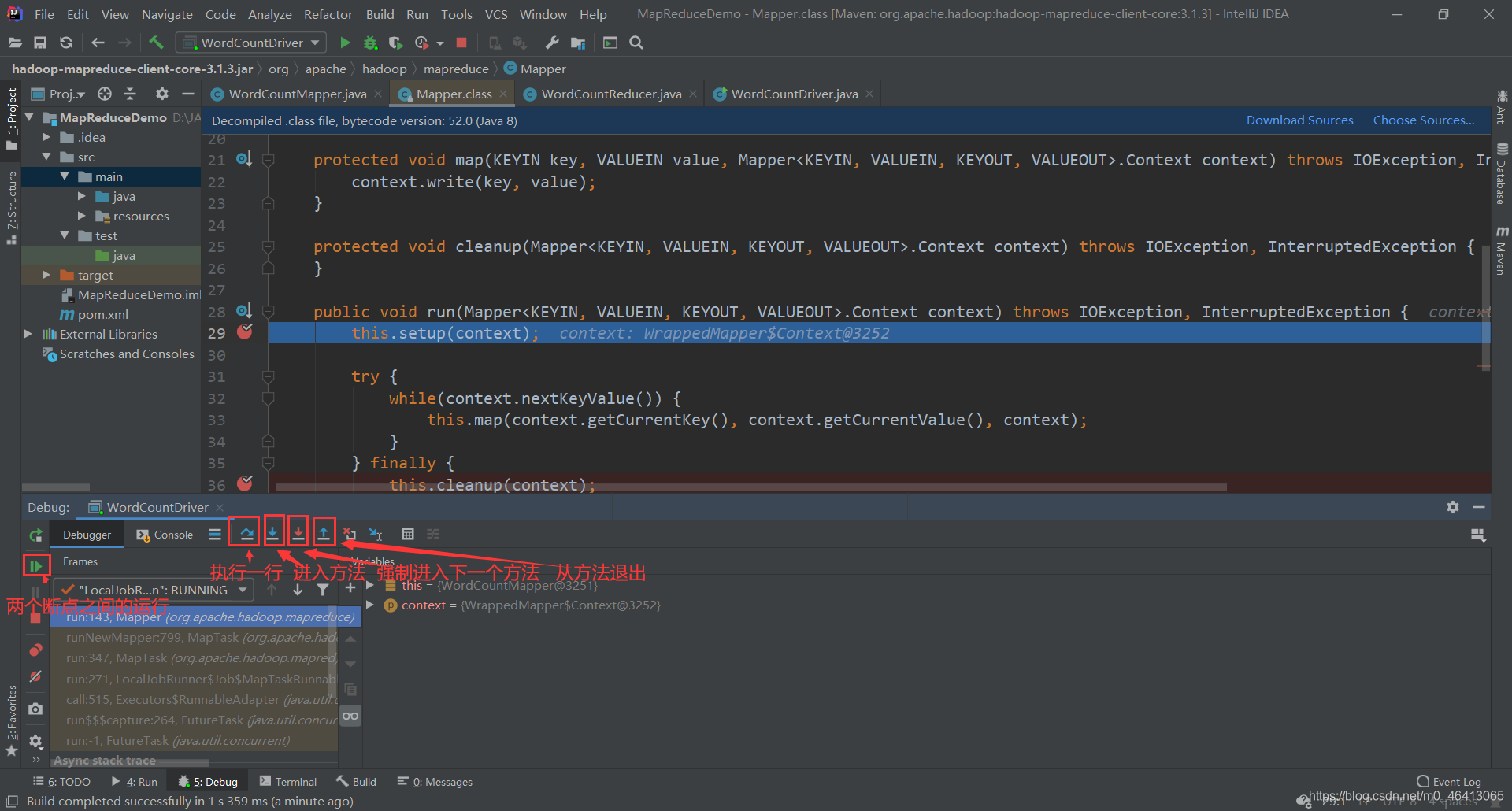
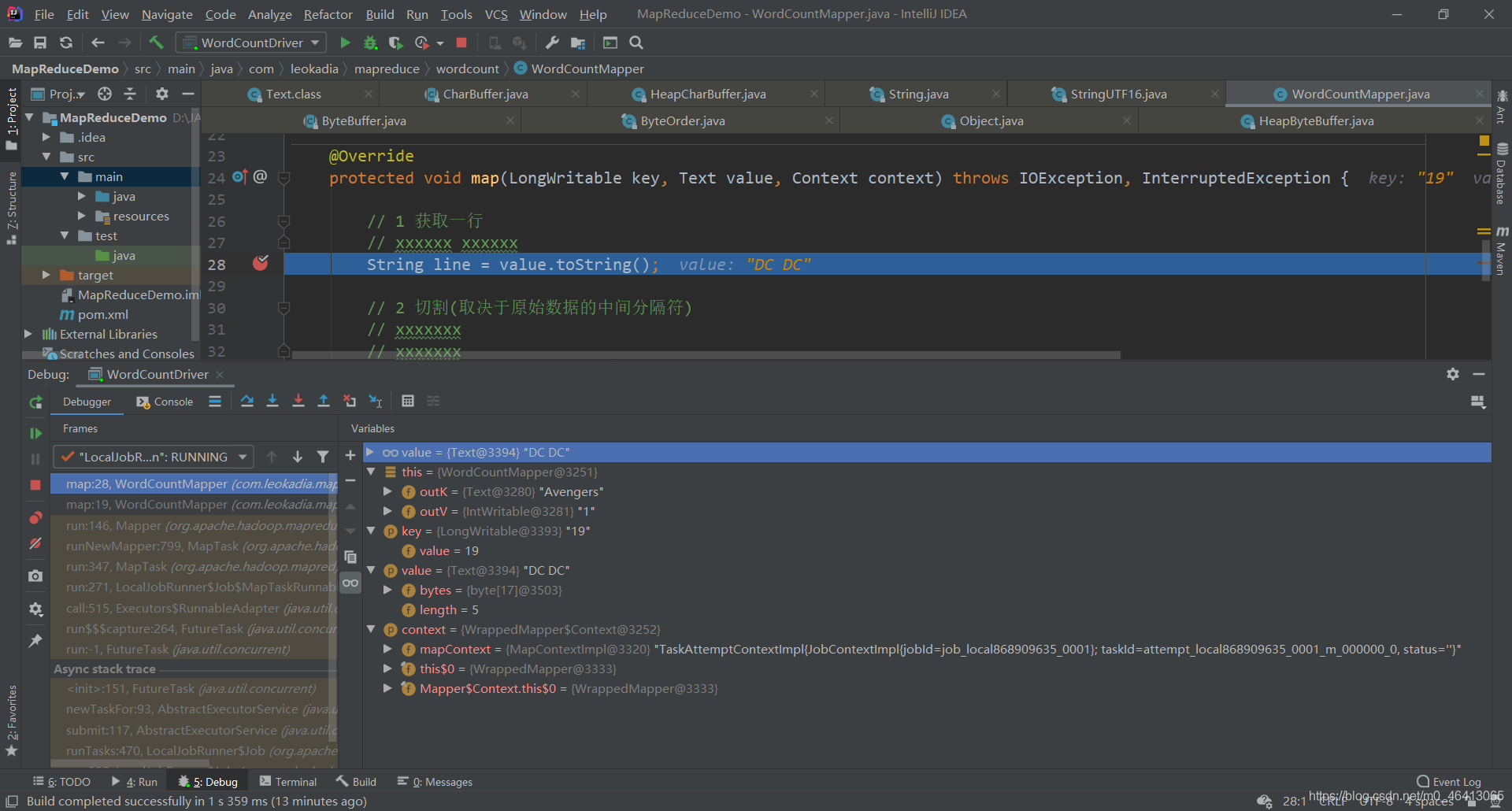 通过调试可以更清楚的理解机制
通过调试可以更清楚的理解机制 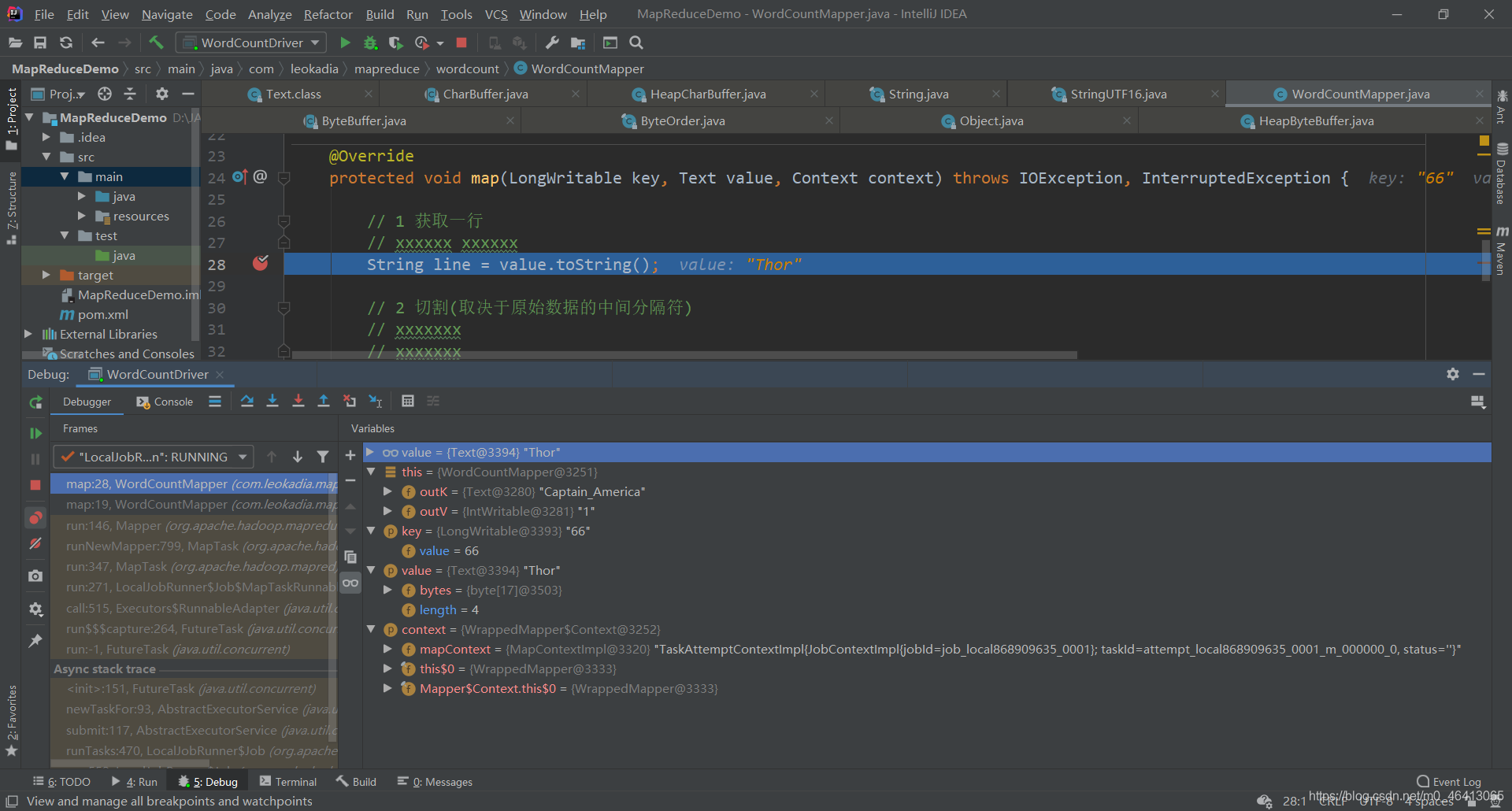
 打包完毕,生成jar包
打包完毕,生成jar包 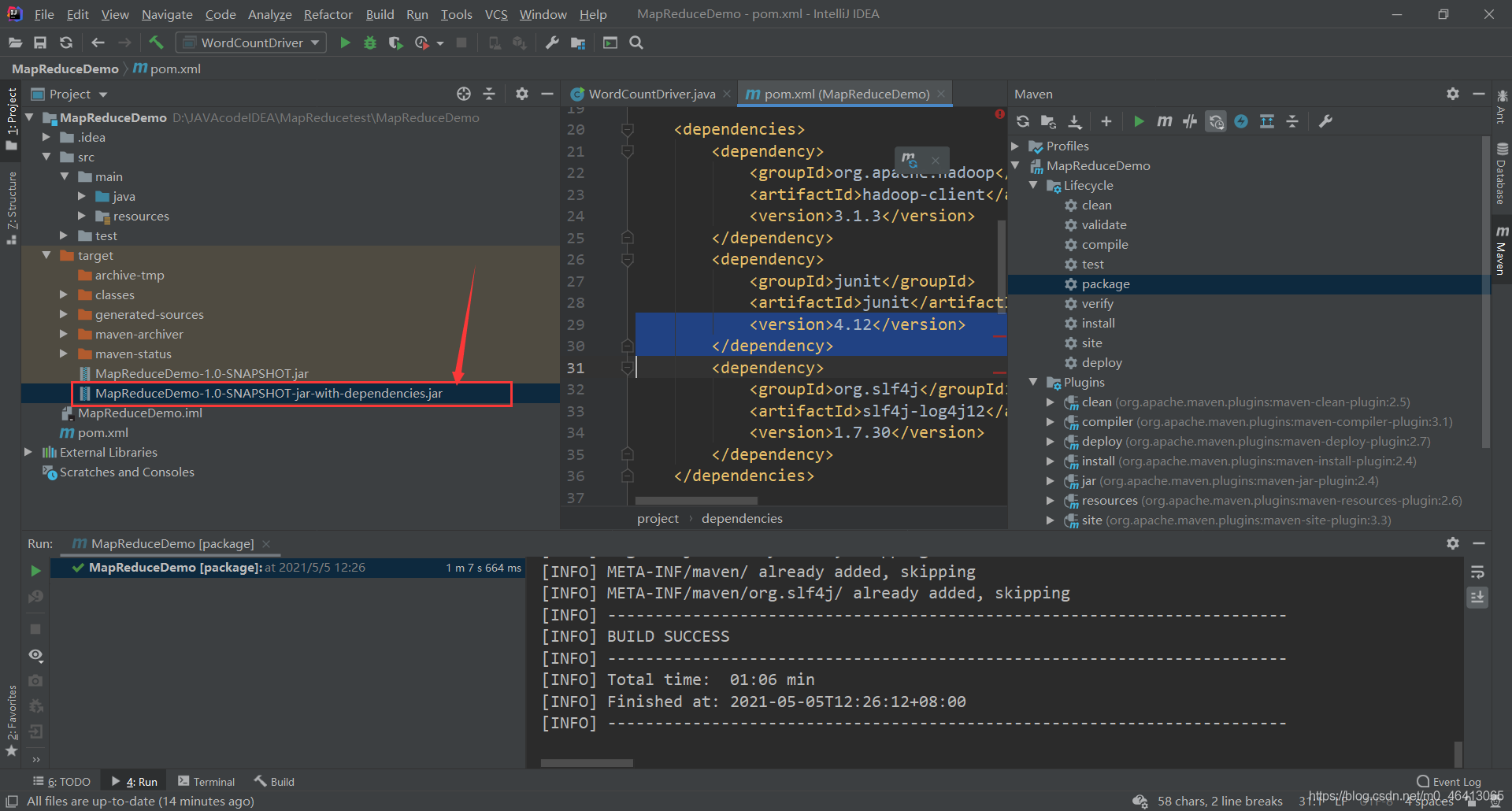 去文件夹里查看一下
去文件夹里查看一下 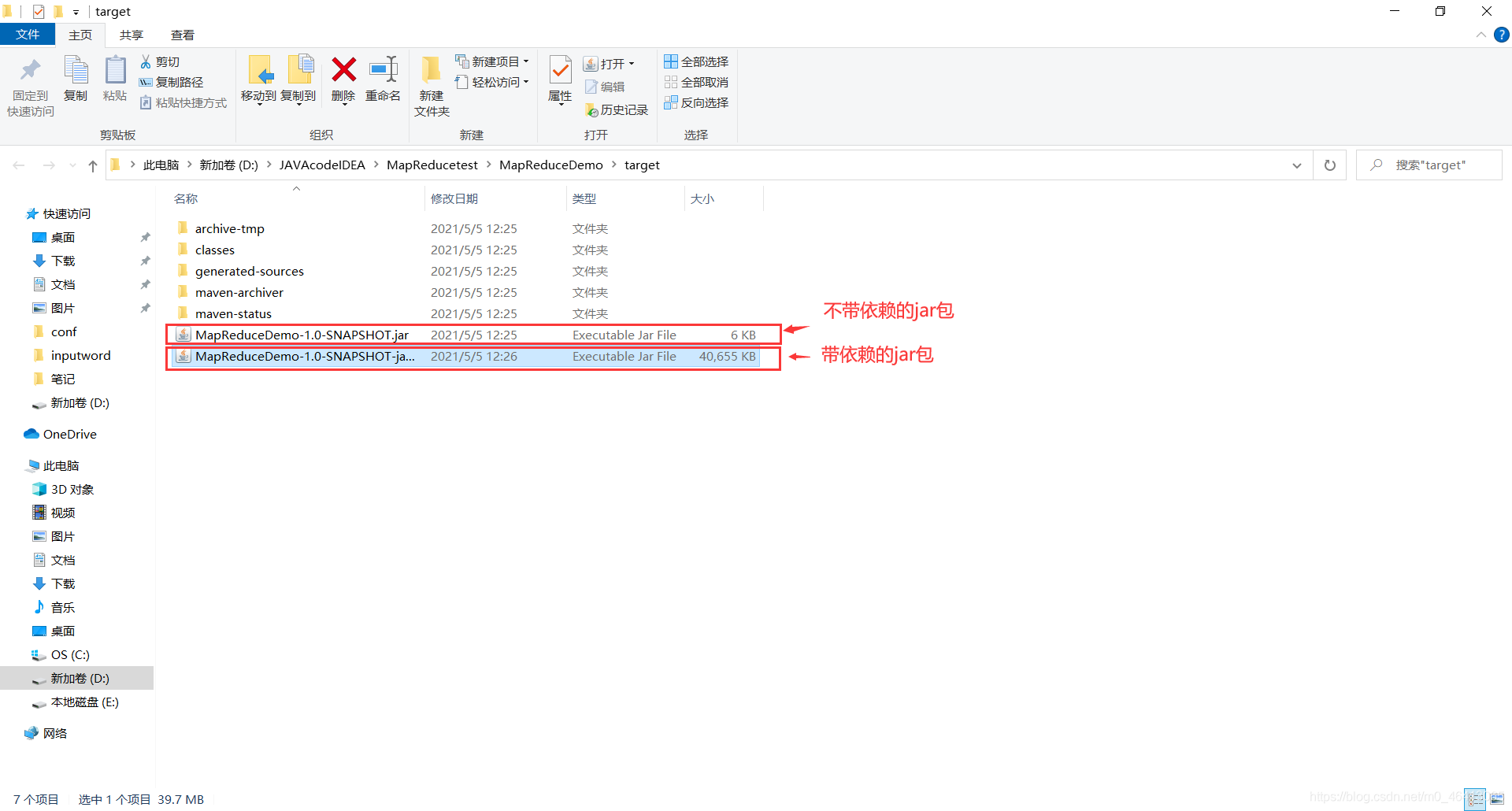 由于我们集群里面配置了相关依赖的内容,用上面的即可
由于我们集群里面配置了相关依赖的内容,用上面的即可 思考: 刚刚的程序中,我们写的路径是本地windows的路径
思考: 刚刚的程序中,我们写的路径是本地windows的路径 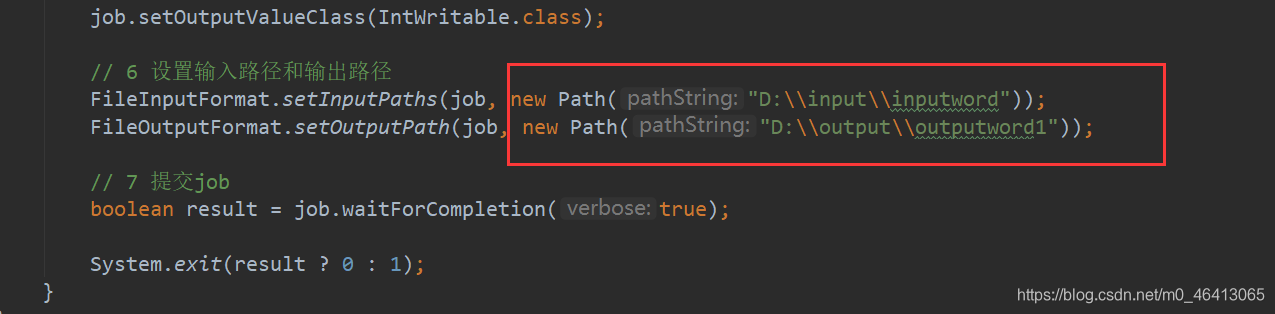 上传到linux环境后它其实没有这个路径,输入输出路径不存在,于是我们需要对它进行修改,改成对应的集群路径 如果想更灵活一点——根据传入的路径来确定输入的路径 回顾之前的
上传到linux环境后它其实没有这个路径,输入输出路径不存在,于是我们需要对它进行修改,改成对应的集群路径 如果想更灵活一点——根据传入的路径来确定输入的路径 回顾之前的 
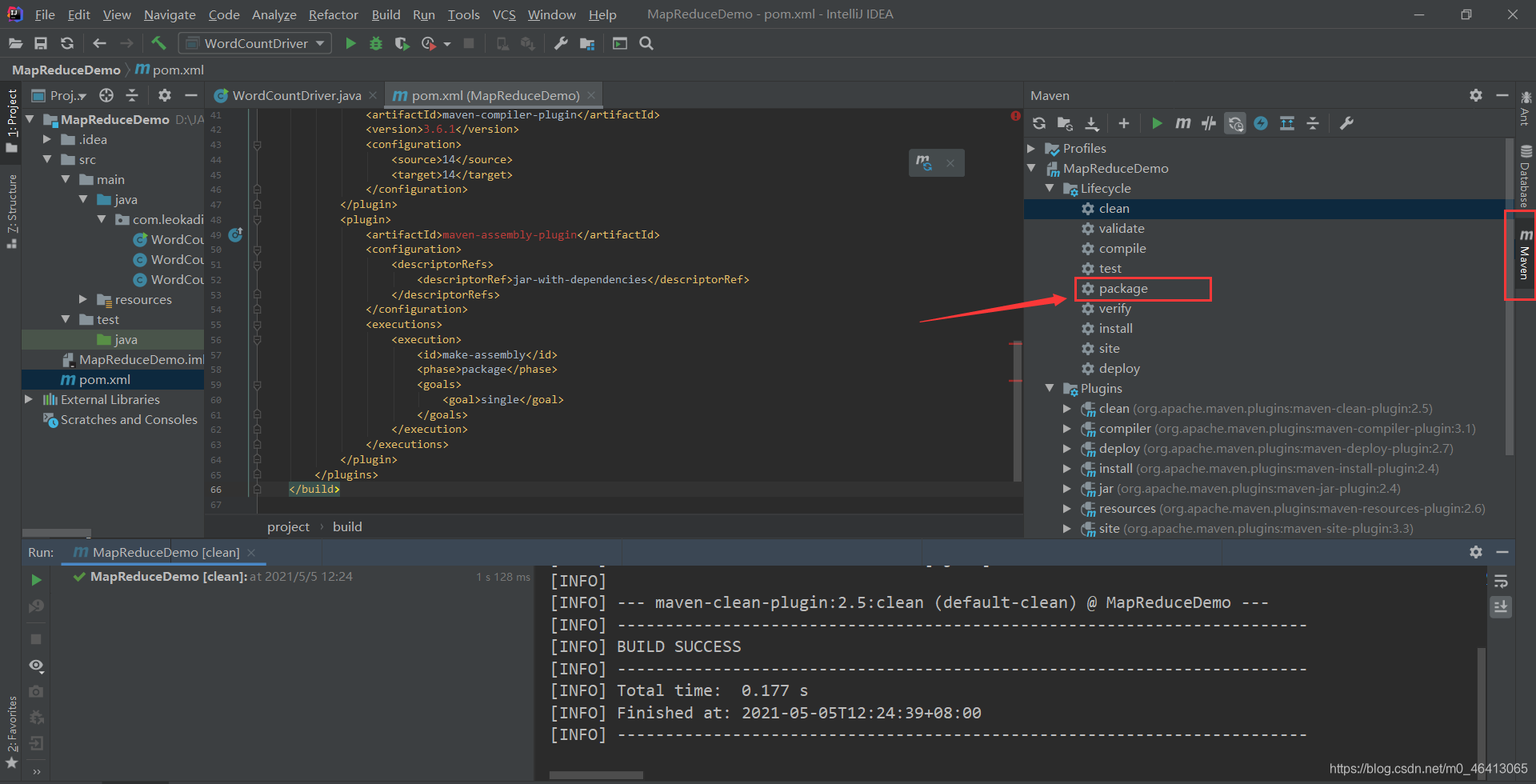
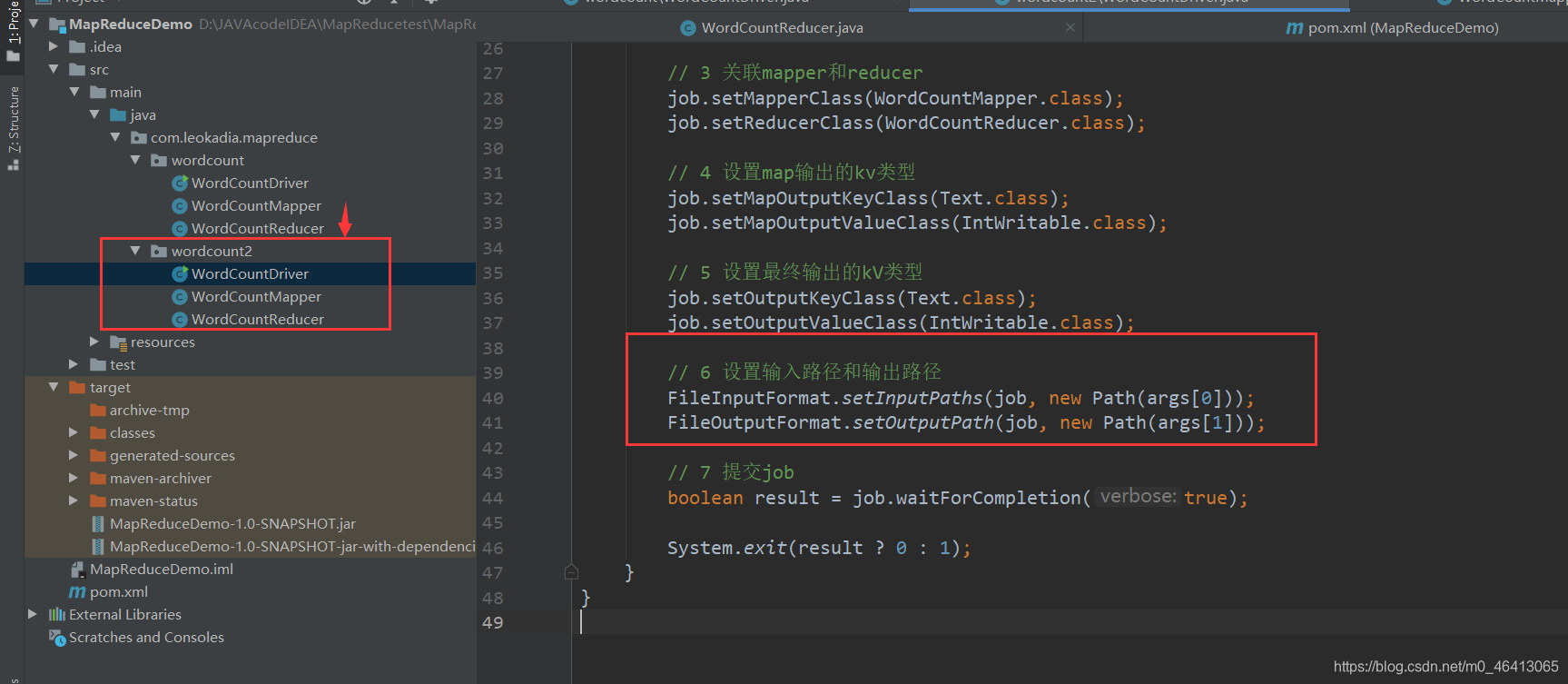 对于新改的程序,先点clean把前面的删掉,再点package进行导包
对于新改的程序,先点clean把前面的删掉,再点package进行导包 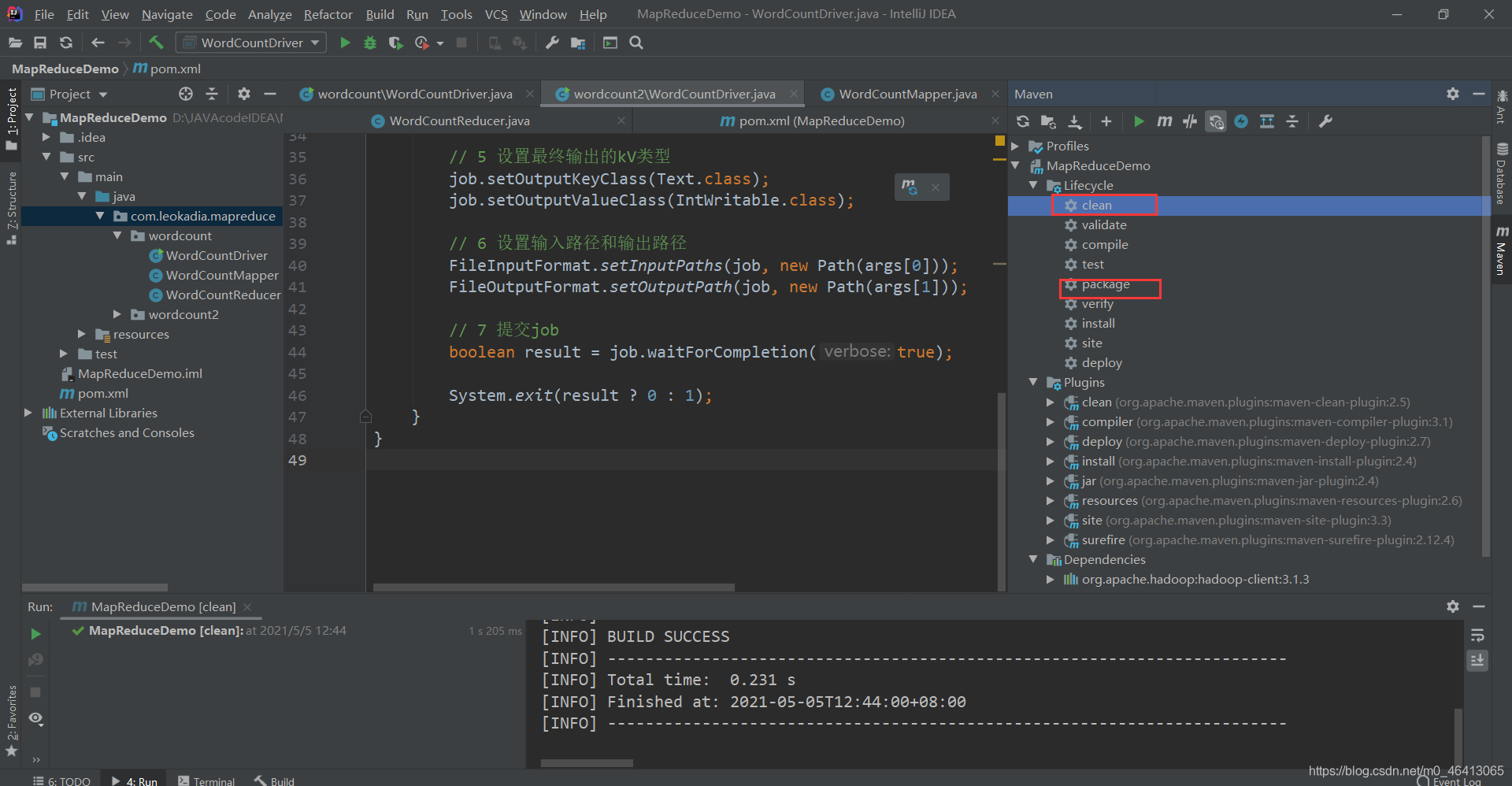

 对于已启动好的集群,直接拖拽
对于已启动好的集群,直接拖拽 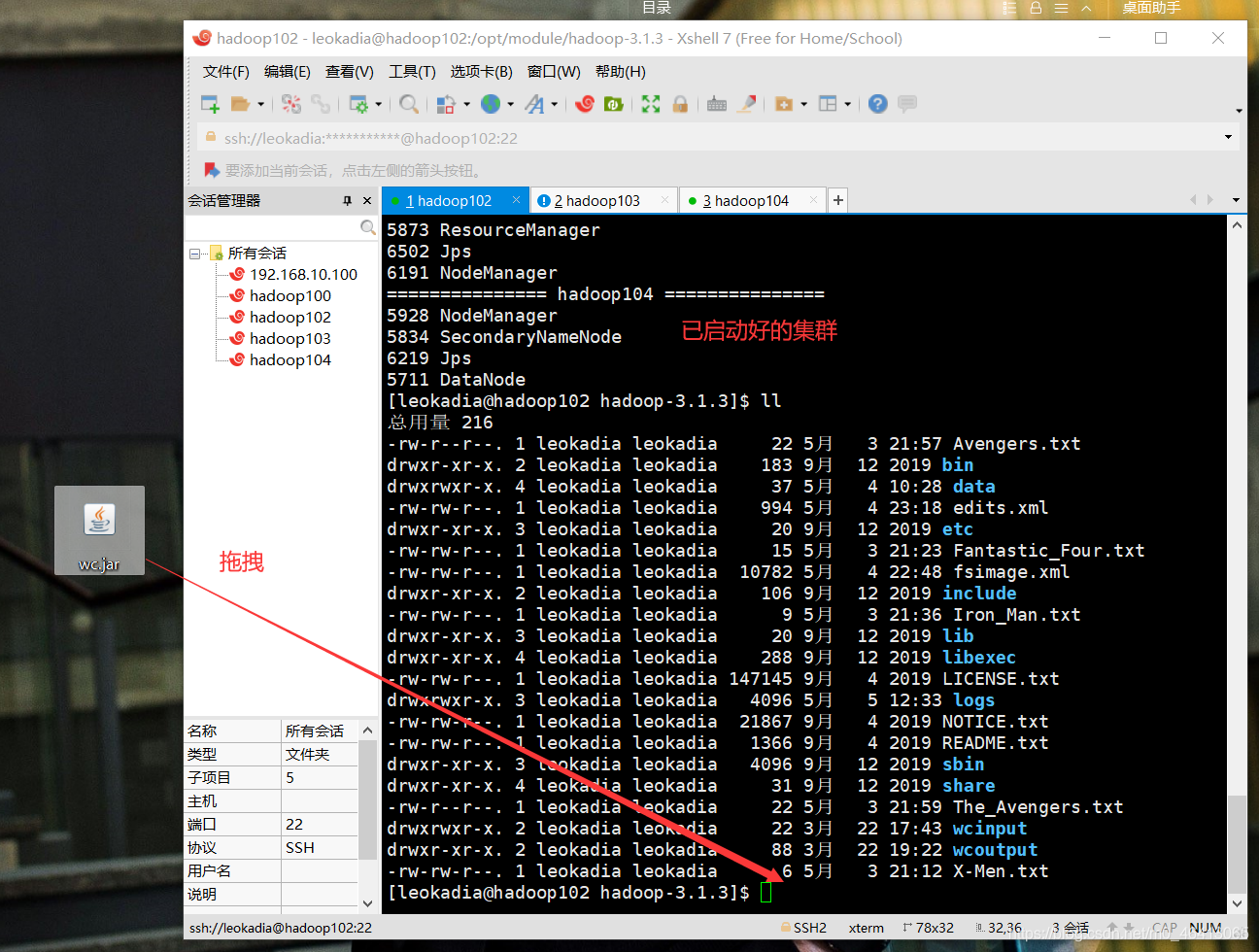
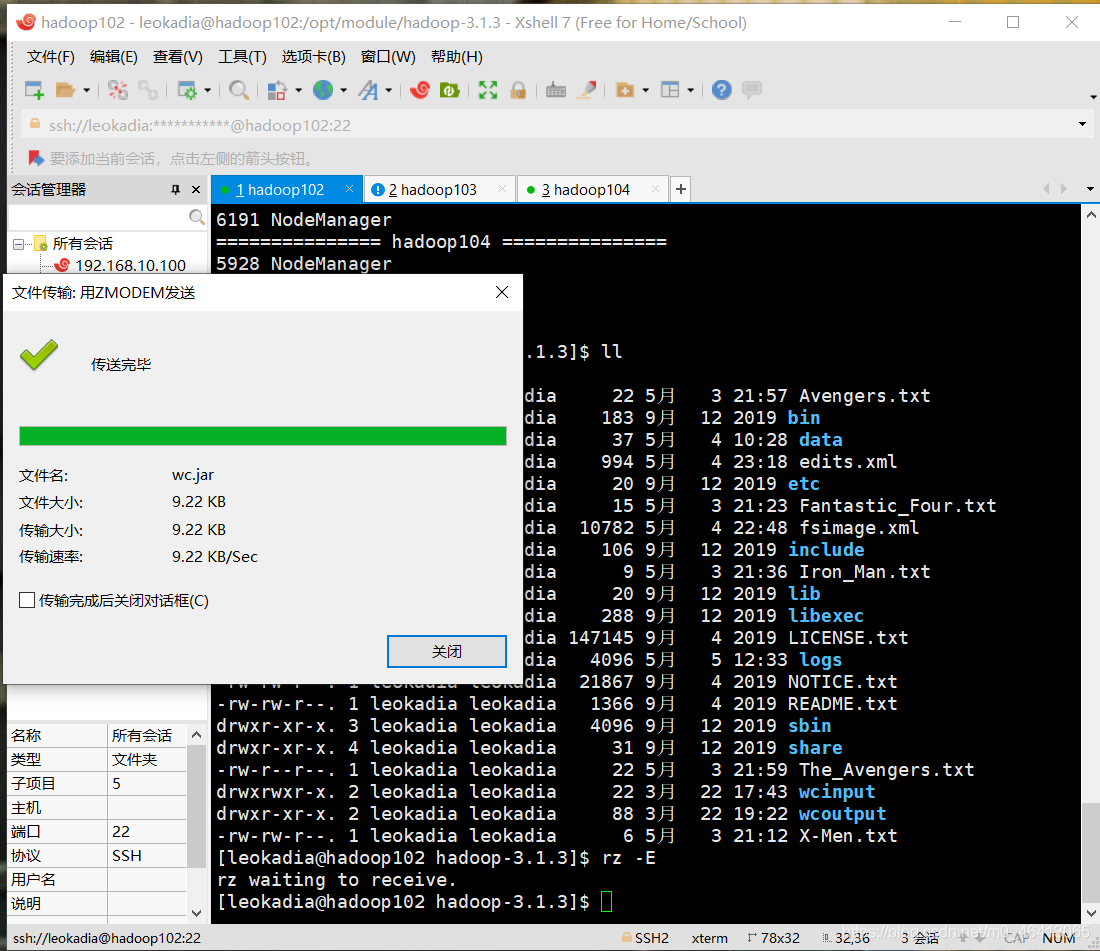 jar包导入完毕!
jar包导入完毕!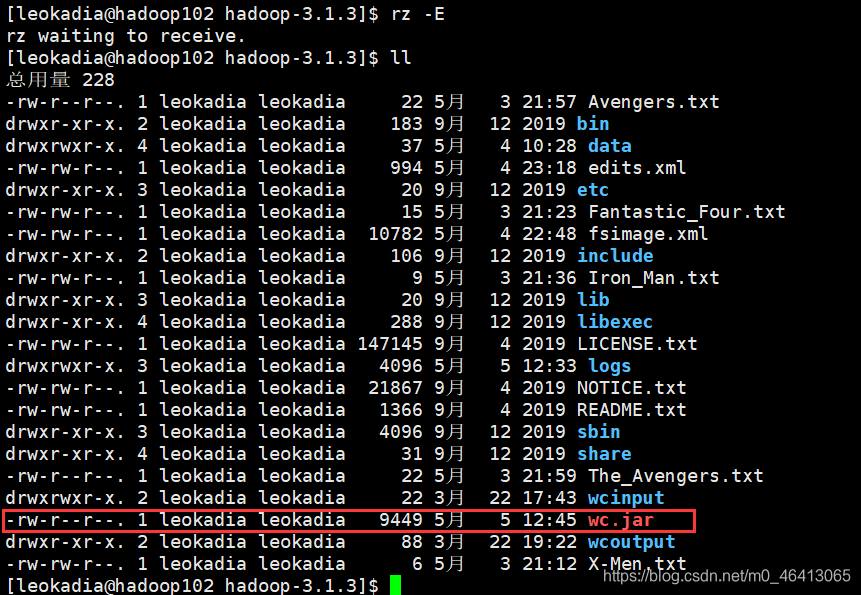
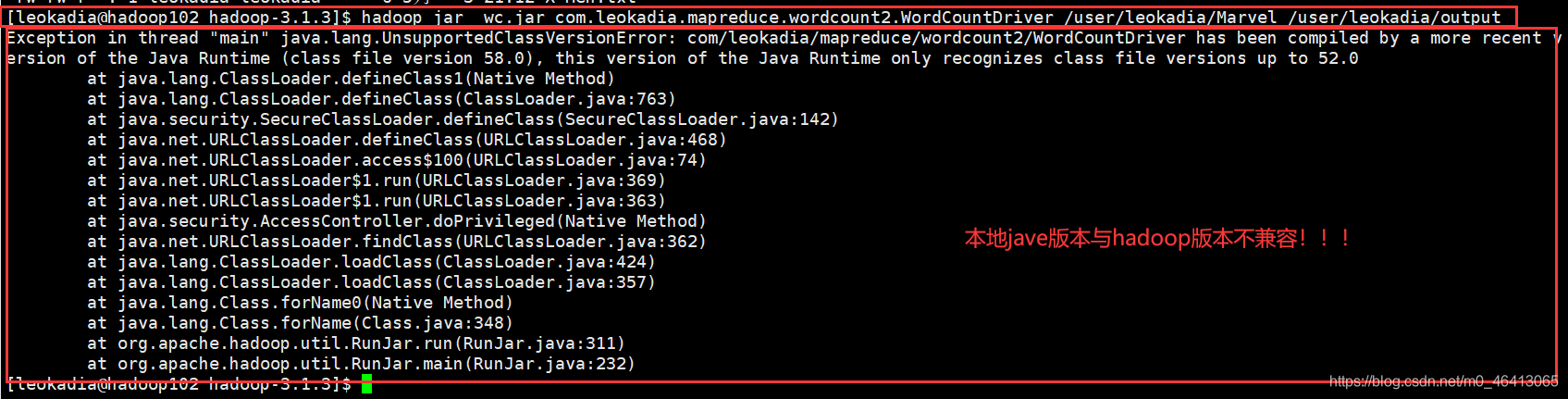
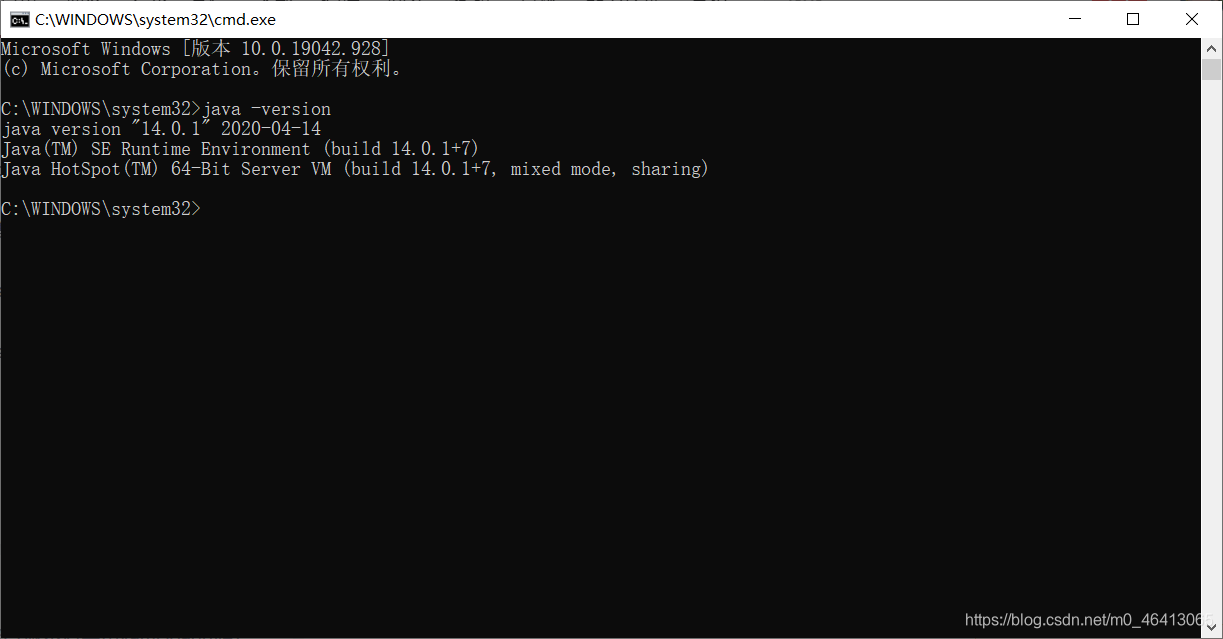 博主hadoop里面装的java版本
博主hadoop里面装的java版本  于是,然后经过查证,hadoop3.x目前只支持jdk1.8 博主只好将本地的jdk版本改成8
于是,然后经过查证,hadoop3.x目前只支持jdk1.8 博主只好将本地的jdk版本改成8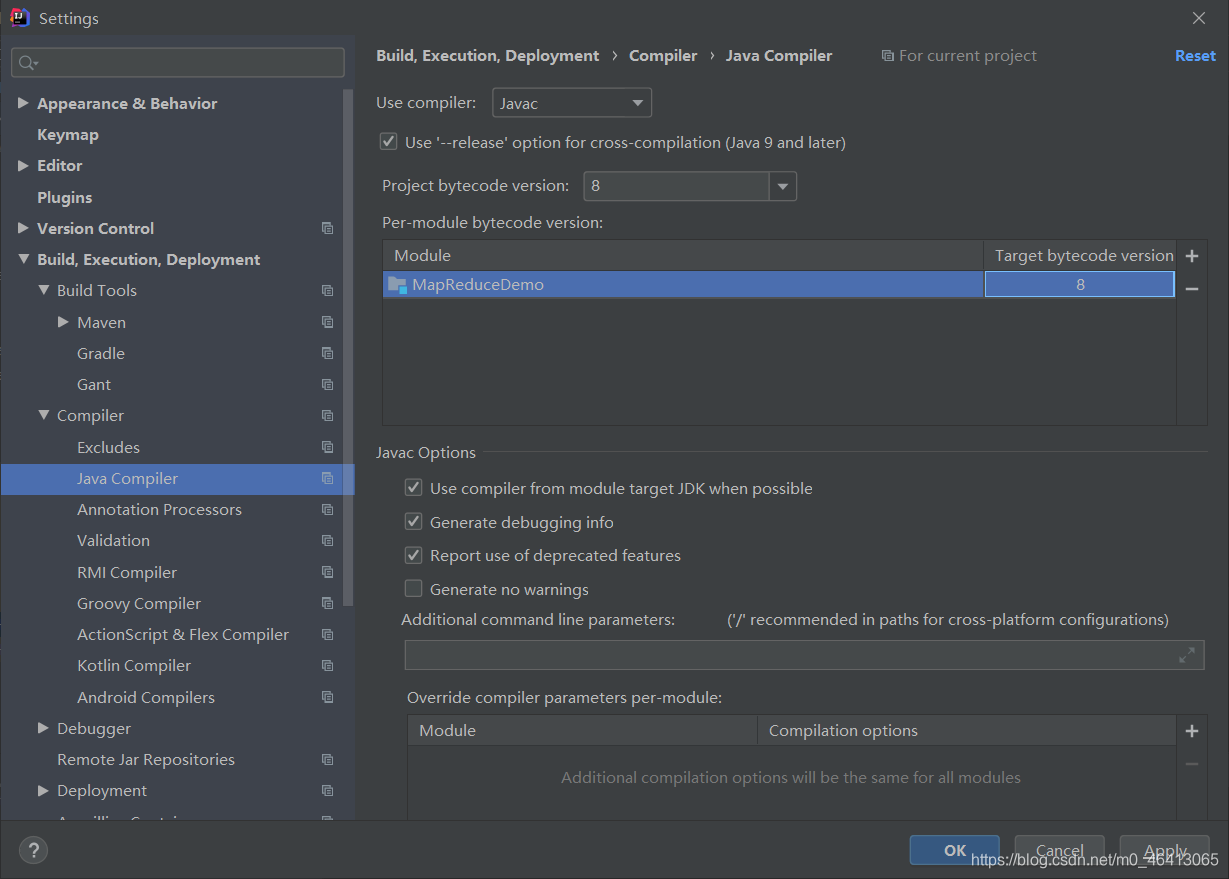
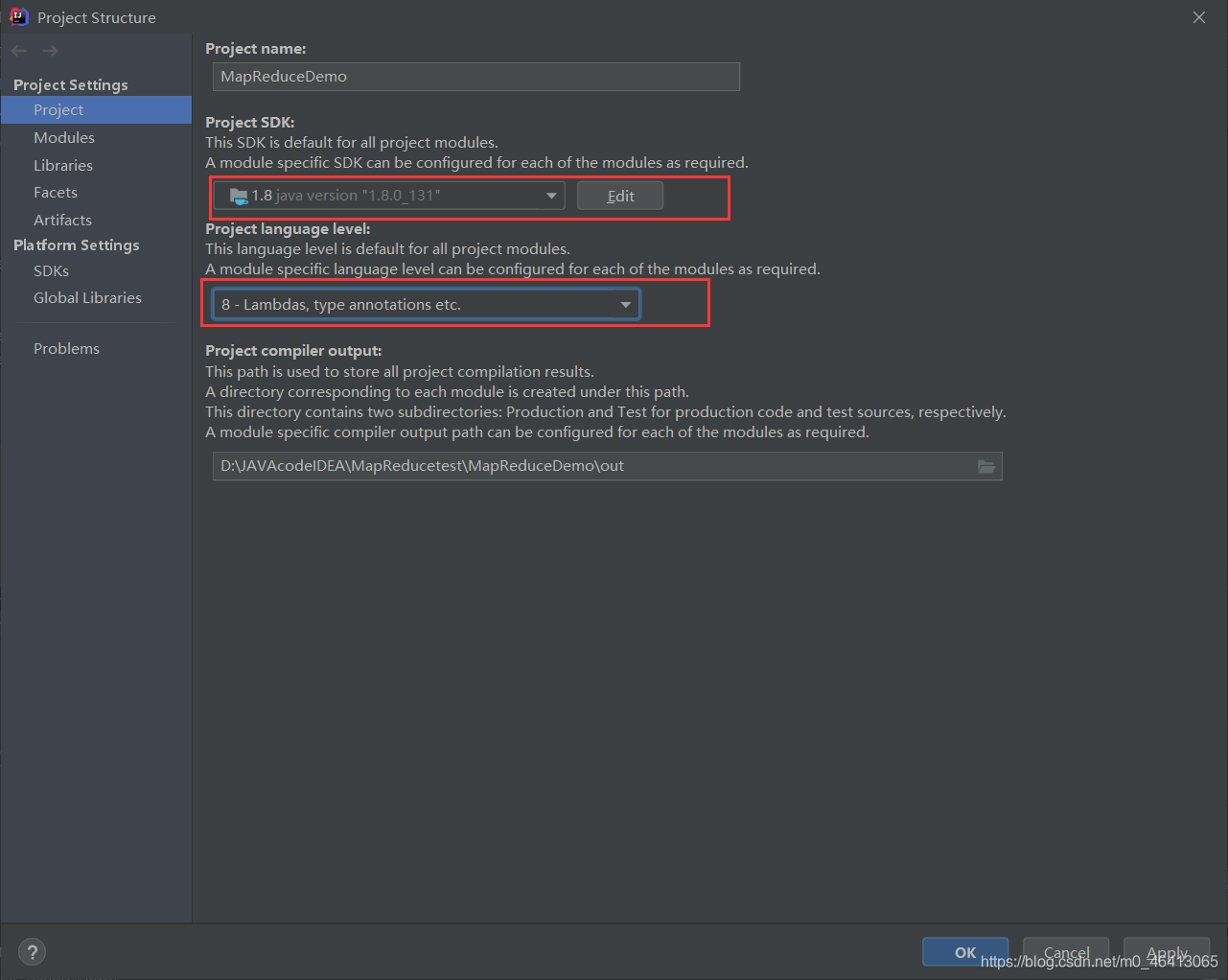
 完结撒花!
完结撒花!【本文地址】